
Оглавление:
1. Что такое Apache Spark.
2. Установка и настройка Apache Spark.
3. Запуск распределенных вычислений в Apache Spark (на примере скрипта python).
Что такое Apache Spark.
Apache Spark – это универсальная и высокопроизводительная кластерная вычислительная платформа.
Фреймворк создан для того, чтобы охватить более широкий диапазон рабочих нагрузок, которые прежде требовали создания отдельных распределенных систем, включая приложения пакетной обработки, циклические алгоритмы, интерактивные запросы и потоковую обработку. Поддерживая все эти виды задач с помощью единого механизма, Spark упрощает и удешевляет объединение разных видов обработки, которые часто необходимо выполнять в едином конвейере обработки данных. Кроме того, он уменьшает бремя обслуживания, поддерживая отдельные инструменты.
Spark предоставляет простой API на языках Python, Java, Scala и SQL и богатую коллекцию встроенных библиотек. Он также легко объединяется с другими инструментами обработки больших данных. В частности, Spark может выполняться под управлением кластеров Hadoop и использовать любые источники данных Hadoop, включая Cassandra.
Внутренняя реализация Spark обеспечивает эффективное масштабирование от одного до многих тысяч вычислительных узлов. Для достижения такой гибкости Spark поддерживает большое многообразие диспетчеров кластеров (cluster managers), включая Hadoop YARN, Apache Mesos, а также простой диспетчер кластера, входящий в состав Spark, который называется Standalone Scheduler. При установке Spark на чистое множество машин на начальном этапе с успехом можно использовать Standalone Scheduler . При установке Spark на уже имеющийся кластер Hadoop YARN или Mesos можно пользоваться встроенными диспетчерами этих кластеров.
Проще говоря, Spark - это отдельный программный продукт, который может эффективно взаимодействовать с такими компонентами Hadoop как: YARN, HDFS, Hive, HBase.
Установка и настройка Apache Spark.
Скачаем архив с официального сайта . Тут необходимо выбрать версию Spark, я скачал версию spark-2.4.4.
После скачивания архива его нужно разархивировать и перенести извлеченный каталог в /usr/local с помощью команды sudo mv /откуда /куда.
Теперь необходимо настроить переменные окружения для этого запустим редактор (у меня gedit, можно vim или nano):
sudo gedit .bashrc
В конец добавить следующие строки с переменными:
export SPARK_HOME=/usr/local/spark-2.4.4
export PATH=$PATH:$SPARK_HOME/bin
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=python3
Выйдем из редактора и применим настройки:
source .bashrc
Теперь необходимо настроить файл spark-env.sh
Перейти в каталог настроек:
cd $SPARK_HOME/conf
Создать файл spark-env.sh из шаблона (template):
sudo cp spark-env.sh.template spark-env.sh
Открыть spark-env.sh в редакторе:
sudo gedit spark-env.sh
И добавить в конец строки:
SPARK_MASTER_HOST=master
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=python3
Сохранить изменения и выйти.
Создать файл slaves из шаблона (template):
sudo cp slaves.template slaves
Открыть slaves в редакторе:
sudo gedit slaves
Прописать здесь IP-адреса (или имена как у меня) всех подчиненных машин кластера(worker в spark) мастер также может выступать в роли worker-а (как в моем примере).
master
1VM
2VM
Сохранить изменения и выйти.
Все практически настроено, осталось только скопировать наши настройки (весь каталог spark) на подчиненные машины.
Сначала на всех подчиненных узлах выпонить:
- создать каталог Spark:
sudo mkdir /usr/local/spark-2.4.4
Назначить владельцем каталога пользователя (в нашем примере hduser):
sudo chown hduser:hadoop -R /usr/local/spark-2.4.4
Теперь можно синхронизировать каталоги, я пользуюсь утилитой rsync но можно и scp:
sudo rsync -avxP /usr/local/spark-2.4.4/ hduser@1VM:/usr/local/spark-2.4.4
и на вторую машину:
sudo rsync -avxP /usr/local/spark-2.4.4/ hduser@2VM:/usr/local/spark-2.4.4
Все готово к запуску, перейдем в каталог:
cd $SPARK_HOME/sbin
запустим spark на всех подчиненных узлах с помощью скрипта:
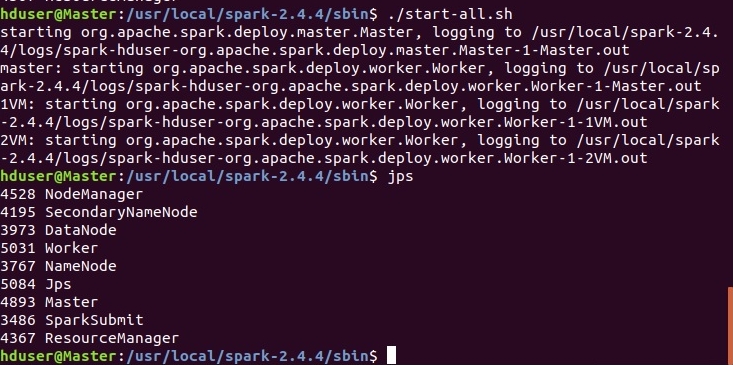
./start-all.sh
При удачном запуске увидим следующее:
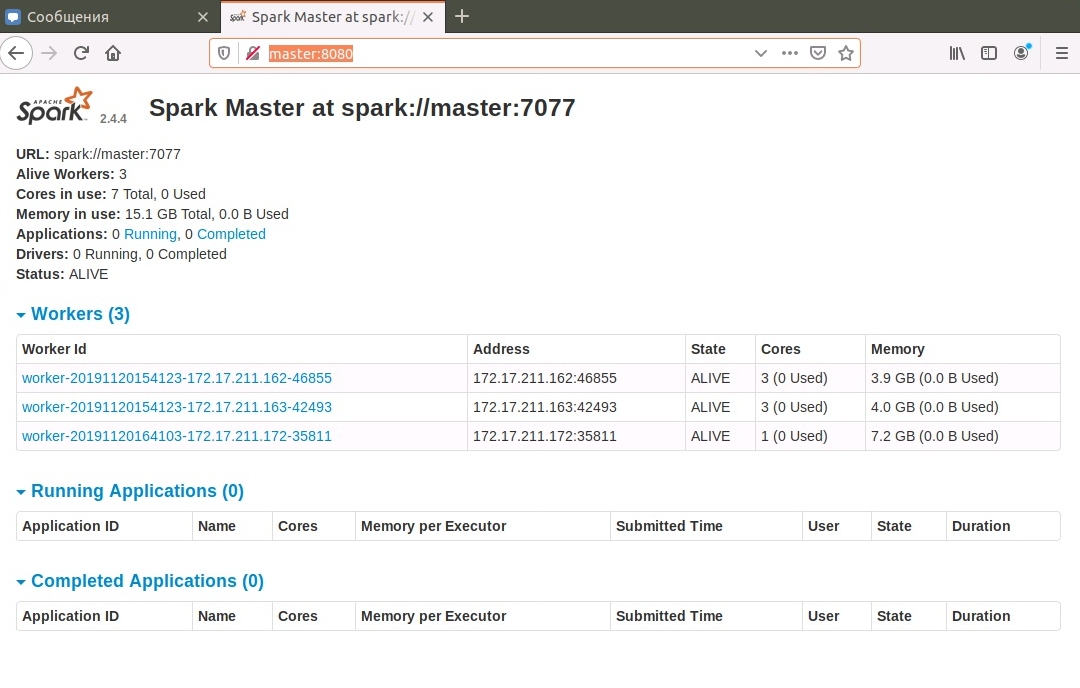
На мастере, порт 8080, доступен веб-интерфейс:
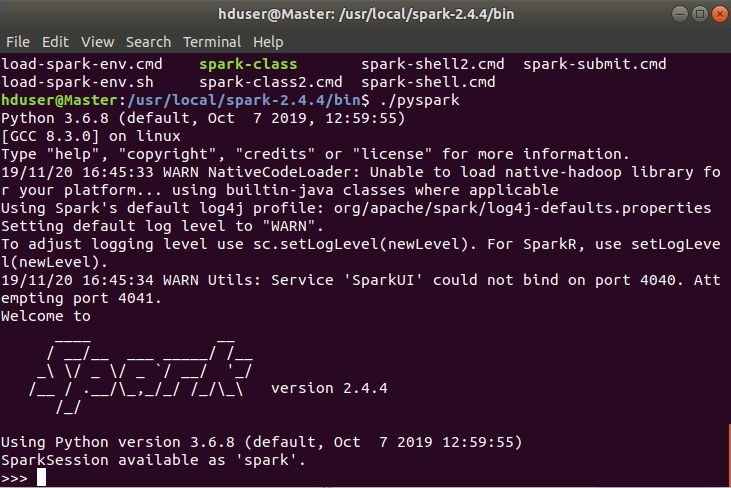
Также доступна командная строка pyspark. Она запускается из каталога $SPARK_HOME/bin:
./pyspark
При удачном запуске увидим следующее:
Все готово к распределенной обработке, приступим!
Запуск распределенных вычислений в Apache Spark (на примере скрипта python).
В этом разделе запустим скрипт python для подсчета слов в произведениях нашего любимого Уильяма Шекспира (в моем примере файл william.txt).
Для этого нам понадобится любой текстовый файл, который нужно загрузить в HDFS из локальной директории (в примере /home/hduser/william.txt):
Создадим входной каталог HDFS: hadoop fs -mkdir /input
Загружаем исследуемый файл в HDFS: hadoop fs -put /home/hduser/william.txt /input
Проверим, загрузился ли файл командой: hadoop fs -ls /input
Далее нам нужен сам скрипт wcount.py
Аккуратнее с форматированием файла! В синтаксисе python отступы важны!
Обратить внимание на следующие строки:
f = sc.textFile("hdfs://Master:9000/input/*.txt") - здесь указан входной каталог, где хранится наш текстовый файл.
counts.saveAsTextFile("/home/hduser/res/") - выходной каталог результата в локальной директории, каталог res не должен существовать, его создает сама программа, в противном случае ошибка.
Сам скрипт я создал в корневом каталоге spark, создав в нем файл и скопировав из браузера код:
sudo gedit $SPARK_HOME/wcount.py
Запуск скриптов осуществляется с помощью утилиты spark-submit в каталоге $SPARK_HOME/bin
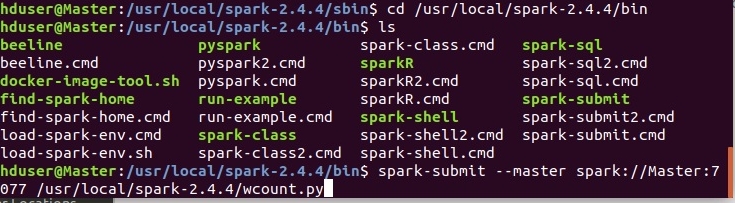
Синтаксис команды:
spark-submit —master spark://Master:7077 /usr/local/spark-2.4.4/wcount.py
Вместо имени хоста-мастера может быть его IP-адрес.
Все готово! Запускаем!
Процесс выполнения подробно логгируется, что наводит на мысли о серьезности производимых вычислений!)))
Итог при успешном завершении должен быть такой:
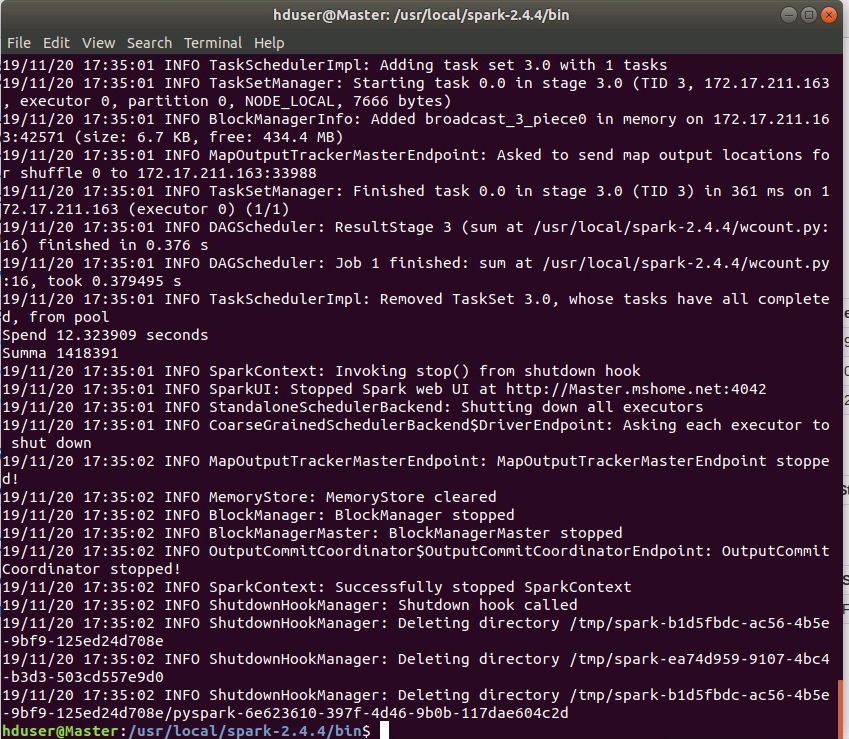
Задача выполнена, результат в каталоге /home/hduser/res/ файл part-00000! В нем приведены встретившиеся слова и напротив - их частота встречаемости.
Логи выполненной задачи также доступны в веб-интерфейсе:
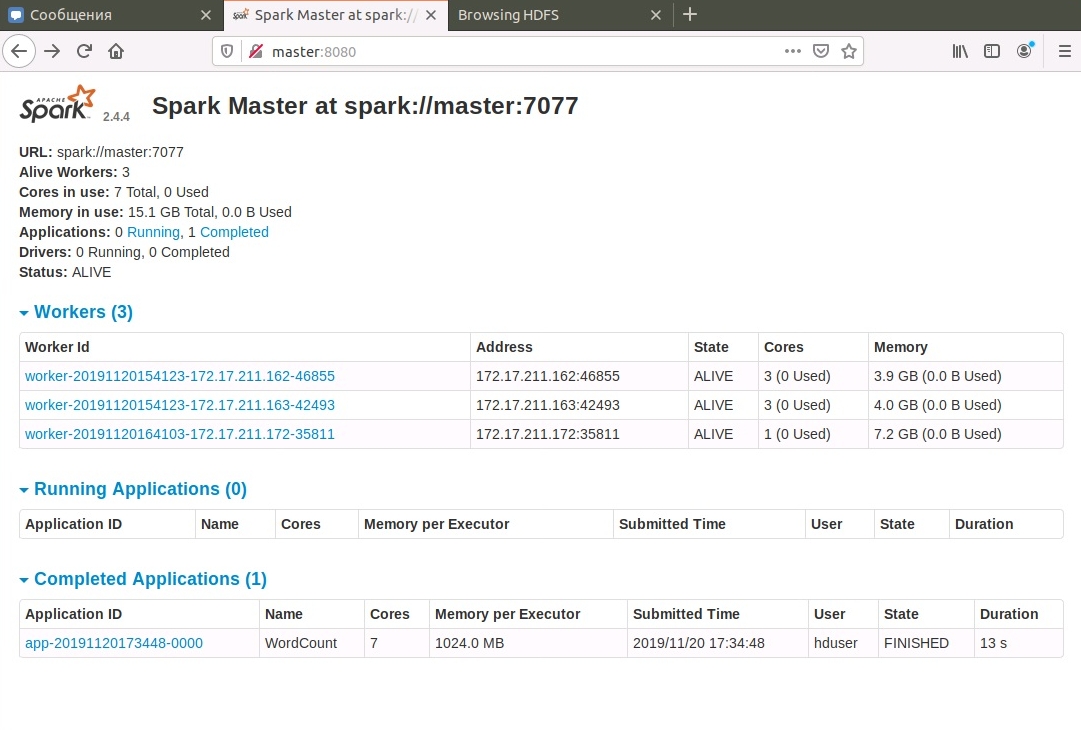
Вот как-то так, вопросы и критика принимаются в группе в контакте, или прямо здесь, в комментариях, доступных после регистрации.
Комментарии
Комментировать могуть только зарегистрированные пользователи