
Оглавление:
1. Что такое Apache Zeppelin.
2. Установка и настройка Apache Zeppelin.
3. Apache Zeppelin настройка интерпретатора Hive.
4. Apache Zeppelin настройка интерпретатора Spark.
5. Анализ данных в Apache Zeppelin (Hive).
6. Анализ данных в Apache Zeppelin (Spark).
1. Что такое Apache Zeppelin.
Apache Zeppelin - это интерактивная среда с web-интерфейсом, позволяющая взаимодействовать с различными источниками данных, обрабатывать эти данные с помощью языков R и Python, а так же визуализировать результаты анализа.
Обща концепция Apache Zeppelin похожа на Jupyter Notebook, где каждый проект представляет собой файл-ноутбук, состоящий из параграфов. Главной особенностью Zeppelin является концепция интерпретаторов, с помощью которых можно настроить параметры подключения к источникам данных или конфигурацию языка программирования. Так же очень полезна такая штука, как интеграция Zeppelin со Spark и наличие интерпретатора для модуля PySpark.
Самое главное достоинство Apache Zeppelin - простая система визуализации результатов с помощью встроенных инструментов, поэтому не надо париться с matplotlib, например. Визуализаторы настраиваемые, что позволяет по-разному представлять результаты.
Итак, приступим к установке и настройке.
2. Установка и настройка Apache Zeppelin.
Скачаем Apache Zeppelin отсюда, в результате будет скачан архив zeppelin-0.8.2-bin-all.tgz. Далее распакуем архив и скопируем содержимое полученного каталога по следующему пути /usr/local/zeppelin-0.8.2/
Если вы дочитали до этой статьи, то уже знаете, как разархивировать и перемещать каталоги в Линукс, если нет, ознакомьтесь с более ранними статьями.
Теперь можно приступить к настройке, начнем с файла zeppelin-env.sh. Сначала нужно создать этот файл в каталоге установки Zeppelin (у меня /usr/local/zeppelin-0.8.2/conf) из существующего шаблона (template) с помощью команды sudo cp zeppelin-env.sh.template zeppelin-env.sh.
Открыть файл для редактирования:
/usr/local/zeppelin-0.8.2/conf$ sudo gedit zeppelin-env.sh
Теперь нужно раскомментировать или создать (если их нет) следующие параметры:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 - путь к jvm/jdk.
export MASTER=spark://master:7077 - имя и порт spark-мастера. Вместо имени (в примере master) может быть IP-адрес.
export SPARK_HOME=/usr/local/spark-2.4.4 - каталог, где установлен spark.
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.9.1/etc/hadoop - каталог, где установлен hadoop.
export PYSPARK_PYTHON=/usr/bin/python3 каталог, где установлен python, в ubuntu по умолчанию в этом каталоге.
Сохраняем, выходим.
Теперь создаем из шаблона и редактируем файл zeppelin-site.xml
В этом файле меняем следующие параметры:
zeppelin.server.addr - значение (value) имя или IP-адрес машины, где установлен Zeppelin.
zeppelin.server.port - порт web-сервера, у меня 8090.
Запускаем сервер с правами администратора: sudo /usr/local/zeppelin-0.8.2/bin/zeppelin-daemon.sh start
Все готово, запускаем браузер, набираем в адресной строке http://IP-адрес:8090/
Если все удачно, видим следующую картинку
3. Apache Zeppelin настройка интерпретатора Hive.
Для работы с различными источниками данных и запуска скриптов в Apache Zeppelin используются интерпретаторы. Так как у нас уже есть настроенное хранилище Hive, первым делом настроим данный интерпретатор.
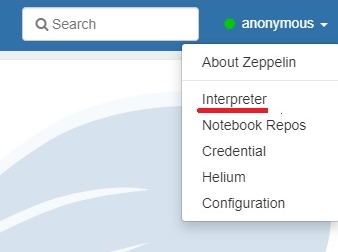
Для этого в веб-интерфейсе Zeppelin необходимо открыть выпадающее меню в верхнем правом углу, где указано имя текущего пользователя (по умолчанию Anonimous). По клику появится выпадающее меню, в котором выбираем Interpreter. В результате появится список стандартных интерпретаторов.
Для работы с SQL-базами данных, для которых требуется jdbc-драйвер, внезапно используется интерпретатор jdbc. Находим его и кликаем по кнопке EDIT справа, как показано на рисунке. В результате поля настроек становятся доступны для редактирования. Самая первая группа параметров представлена в виде имя переменной (name) - значение (value), есть также возможность удалить переменную (крестик в поле action). Ну и внизу можно создать новую переменную (кнопка с плюсиком).
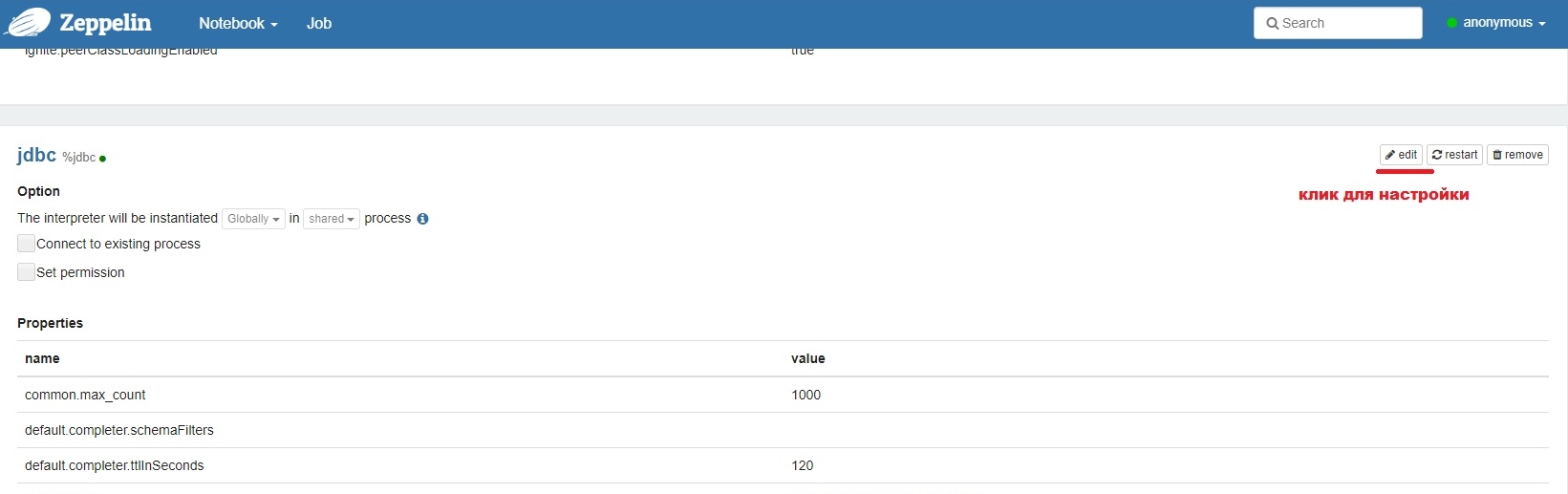
Переменные заполнены по умолчанию для Postgre, поэтому внесем изменения в ряд переменных.
Переменная default.driver необходимо установить значение org.apache.hive.jdbc.HiveDriver
Переменная default.url установить значение jdbc:hive2://Master:10003/default;transportMode=http;httpPath=cliservice;
Эти значения зависят от настроек вашего Hive-сервера.
Master:10003 - имя(или IP-адрес) машины, где запущен hive-thrift сервер и порт (у меня 1003, файл hive-site.xml).
default - имя базы данных hive, к которой подключаемся.
transportMode=http - режим взаимодействия с сервером (у меня http, файл hive-site.xml).
httpPath=cliservice - режим взаимодействия через http (у меня cliservice, файл hive-site.xml).
Переменная default.user необходимо установить значение имя пользователя, настроенного для hive в файле hive-site.xml.
Далее необходимо настроить подключаемые зависимости Dependencies, смотрим рисунок.
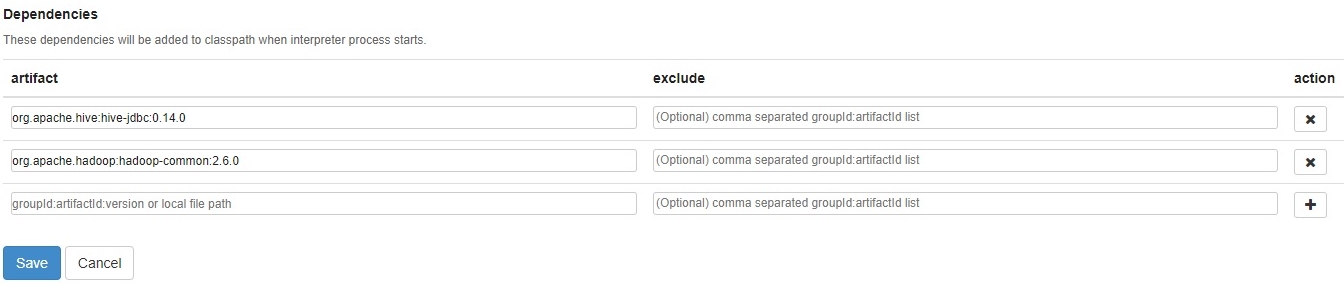
Здесь нас интересует поле artifact, его значения представлены также на рисунке. Это подключаемые библиотеки для hive (org.apache.hive:hive-jdbc:0.14.0) и для hadoop (org.apache.hadoop:hadoop-common:2.6.0). Следует отметить, что здесь можно указать путь к требуемому файлу, далее для MySQL мы рассмотрим данную возможность.
На этом настройка завершена, необходимо нажать кнопку SAVE, после чего, если нет ошибок, интерпретатор будет доступен в параграфах notebook.
4. Apache Zeppelin настройка интерпретатора Spark.
Для настройки интерпретатора в списке (смотрите предыдущий раздел) найти Spark и кликнуть по кнопке Edit в правом верхнем углу, после чего поля с параметрами станут доступны для редактирования.
Для нас важны следующие переменные:
master - установить значение spark://master:7077. Вместо имени может быть IP-адрес мастера Spark.
zeppelin.pyspark.python - указать каталог установки Python нужной вам версии. У меня это /usr/bin/python3.
На этом все, нажимаем на кнопку Save, и можно приступать к работе.
5. Анализ данных в Apache Zeppelin (Hive).
Итак, у нас все готово к работе: данные в Hive загружены, Hive-сервер и Hadoop (HDFS) на мастере запущены, Spark запущен, Zeppelin тоже работает.
Создаем новый Notebook в Zeppelin. Вкладка Notebook->Create new note.
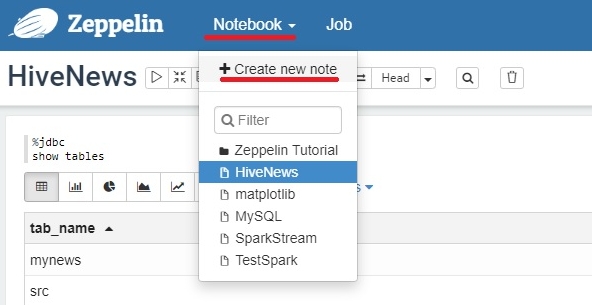
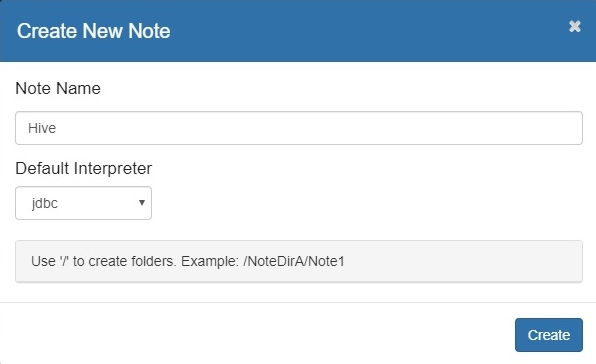
В открывшемся модальном окне указать имя новой записной книжки и интерпретатор по умолчанию, в нашем случае настроенный ранее jdbc (последнее не обязательно, так как в каждом параграфе указываем в начале интерпретатор). Нажимаем кнопку CREATE и оказываемся в новой записной книжке с первым параграфом. В правом верхнем углу каждого параграфа имеется небольшая панель управления, через которую мы можем запускать содержимое параграфа (треугольник или Shift+Enter) или изменять интерфейс.
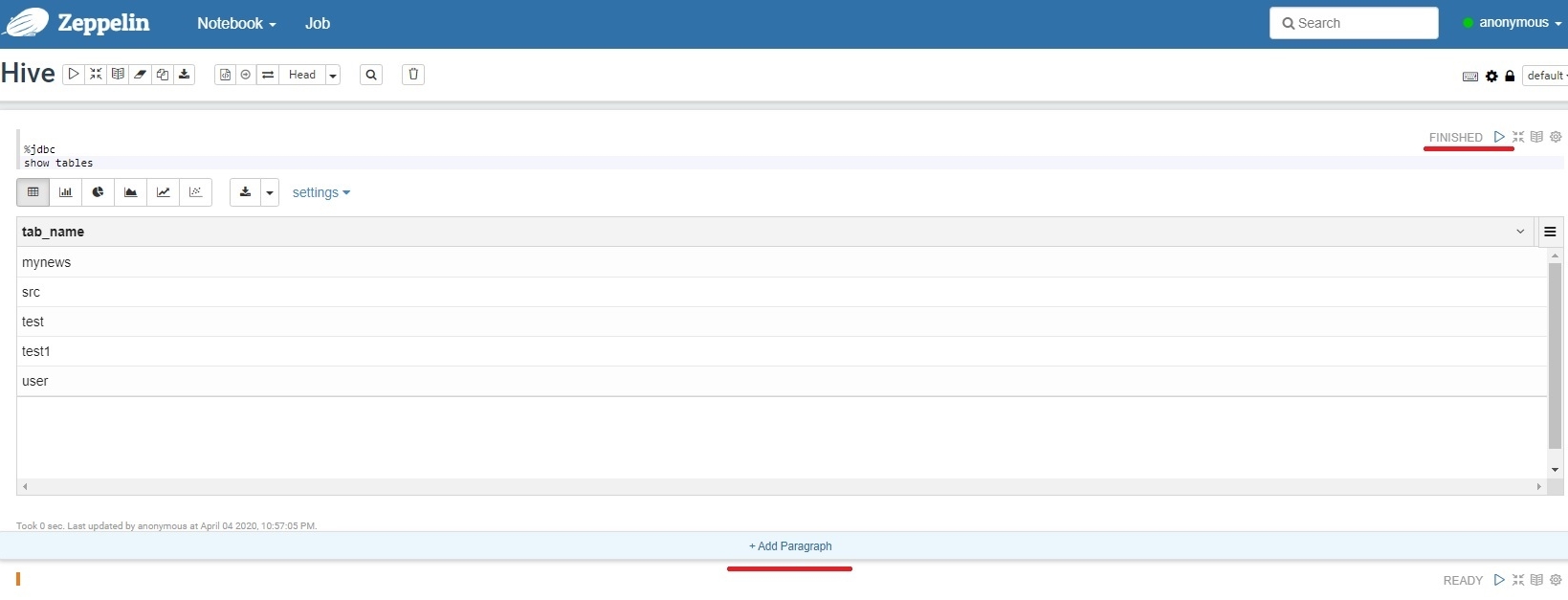
В параграфе пишем наш первый запрос к базе: show tables, нажимаем треугольник в правом верхнем углу (Shift+Enter) и видим список таблиц в нашей базе данных.
Для лучшего понимания параграфов лучше напрямую указывать интерпретатор, в нашем случае это будет выглядеть в параграфе так:
%jdbc
show tables
Теперь можно приступить к выполнению запросов к данным в таблице. Если вы не знаете SQL хотя бы на начальном уровне, делать вам тут нечего, бегом учить азы языка!
Запросы могут выдавать либо множество записей, либо количество записей и умный Zeppelin оформит их для вас должным образом.
Если вы хотите получить записи (например SELECT * FROM table), то он выдаст результат в виде таблицы. Тут я не вижу никаких трудностей, если есть вопросы, спрашивайте в группе Вконтакте.
Для анализа данных нам важны количественные характеристики каких либо событий, например, количество сообщений в день, содержащих какое-то слово или количество всех сообщений от каждого источника. Напомню, что на странице размещено описание моей таблицы и ее дамп.
Для получения количества новостей от каждого новостного агентства необходимо выполнить следующий запрос в новом или в том же параграфе:
select agency, count(*) as cnt from mynews group by agency order by cnt
Результат получаем в виде таблицы, но нам нужна столбиковая диаграмма, поэтому в появившемся меню интерфейса вывода жмем на Bar Chart, вторая кнопка слева и видим чудо!
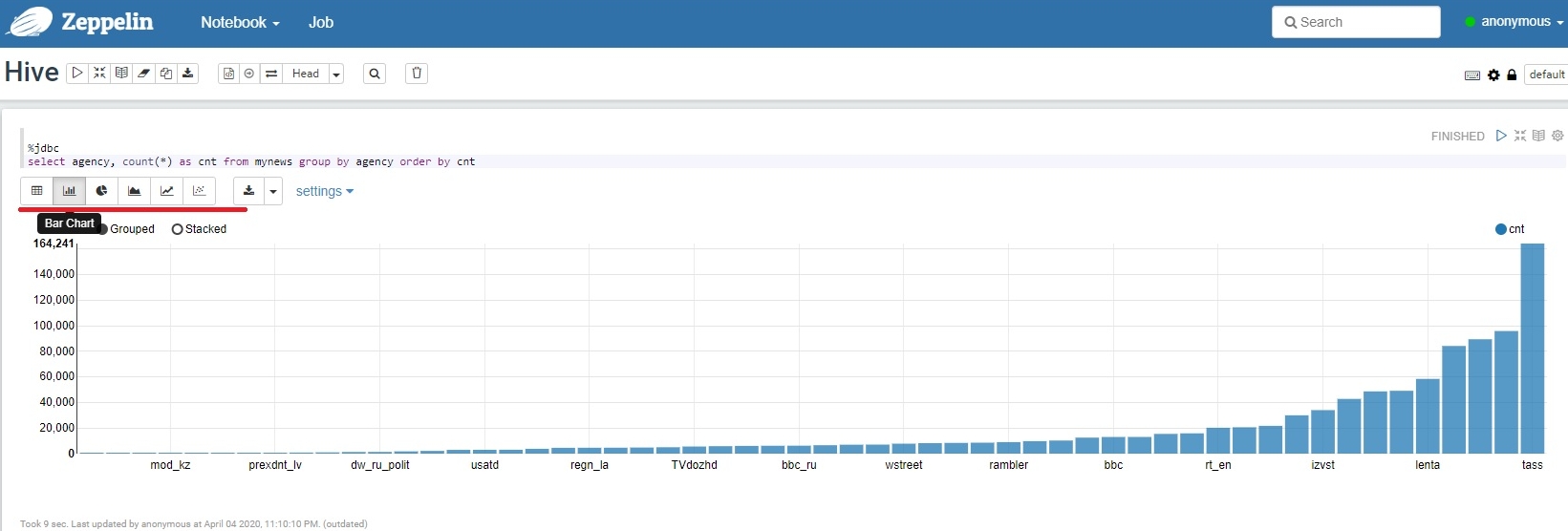
Вы должны получить на выходе что-то похожее на то, что есть на рисунке. Если ничего нет, или график не очень, нужно кликнуть по вкладке Settings и настроить значения по осям с помощью drug-n-drop.
По оси Х(keys) - то, что считаем, по оси Y(values) - значения счета.
Теперь вы готовы для выполнения других запросов, если есть вопросы, пишите в группу Вконтакте.
6. Анализ данных в Apache Zeppelin (Spark).
В предыдущем разделе мы построили красивый график статистики по информационным источникам. Если же выполнить запрос по выборке количества сообщений, содержащих какое-либо слово, мы натолкнемся на некоторые ограничения, связанные с SQL (график увидим ниже). Запрос выглядит так:
SELECT DATE(time_new) as dt , count (*) FROM mynews WHERE text like '%Aramco%' GROUP BY DATE(time_new) order by dt
Дело в том, что на графике будут отражены только те даты, где встречалось заданное слово (в примере Aramco)
Нам же зачастую для подсчета статистики важны и даты с нулевыми значениями, вот тут нам на помощь приходит PySpark!
PySpark - это библиотека для языка Python, позволяющая производить распределенную обработку с использованием Spark. Для понимания библиотеки необходимо изучить ее особенности с помощью дополнительной литературы, например "Изучаем Spark". Сам я ознакомился только с азами, но этого мне хватило для решения первой задачи: дополнить массив данных, полученный с помощью SQL, нулевыми интервалами. Хотя для этого мне понадобился только Python, так как обработка осуществлялась в основном локально.
Приступим. В разделе 4 мы настроили интерпретатор Spark, наш скрипт можно выполнять в нем без указания интерпретатора. Однако нам нужно сравнивать результаты с SQL, поэтому создадим новый параграф в уже имеющемся блокноте Hive и укажем необходимый интерпретатор %spark.pyspark. По умолчанию интерпретаторы уже подключены к записной книжке, но на всякий случай упомяну, что их можно подключить вручную во вкладке Interpreter Bindibg в правом верхнем углу книжки, а не параграфа! Подключенные интерпретаторы подсвечены неким бирюзовым цветом, да ладно, голубоватым! Смотрим рисунок.
Если интерпретатор Spark в нужном цвете, все готово, можно продолжать.
Теперь все готово для преобразования данных, полученных из таблицы Hive. Так как мы собираемся строить график, установим библиотеку matplotlib в консоли ОС с помощью pip.
Из распределенных задач у нас будет только одна - запрос к таблице Hive, это можно делать либо через Spark.sql, либо через Spark.HiveContext.
Воспользуемся первым вариантом:
SDF1 = spark.sql("SELECT DATE(time_new) as dt , count (*) FROM mynews WHERE text like '%Aramco%' GROUP BY DATE(time_new) order by dt")
В результате получаем особый тип распределенных данных - DataFrame, он пока хранится распределённо, чтобы его собрать, используется функция collect().
После этого мы можем работать с данными как с обычным кортежем.
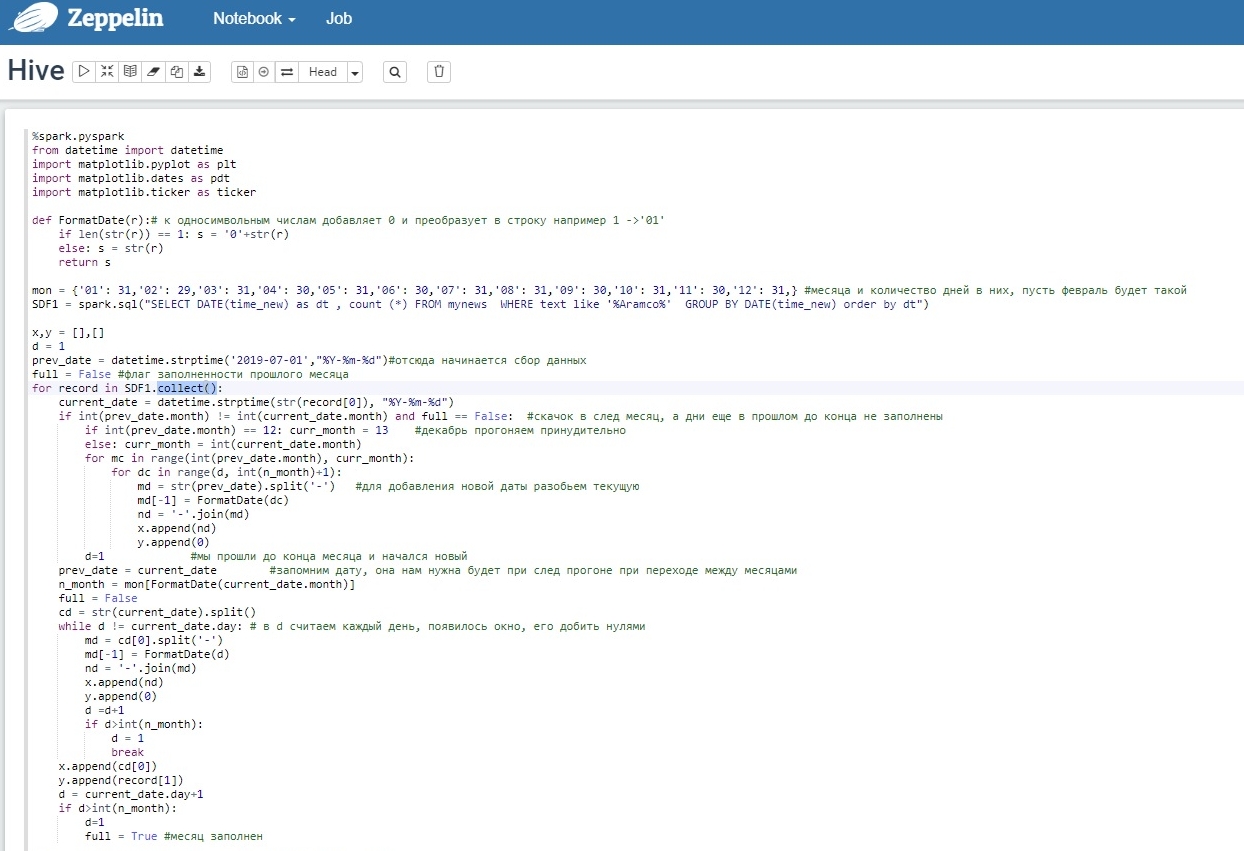
Весь скрипт в скриншот не помещается, поэтому разбил на два: чтение данных и дополнение нулевых дат и построение графика.
Чтение данных и дополнение нулевых дат:
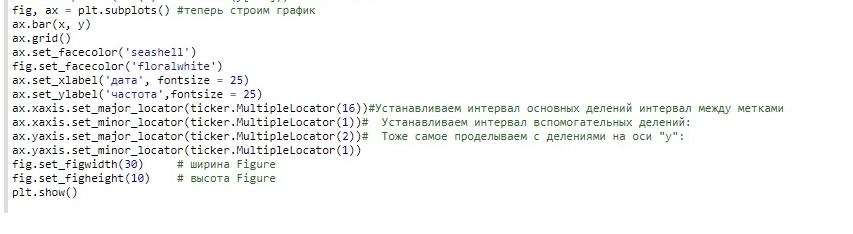
Построение графика:
Жмем треугольник в правом верхнем углу параграфа, ждем продолжительное время при первом запуске, и наблюдаем чудесные графики, в примере приведены для сравнения matplotlib с дополнением нулевых дат и стандартный вывод Zeppelin для запроса к Hive.
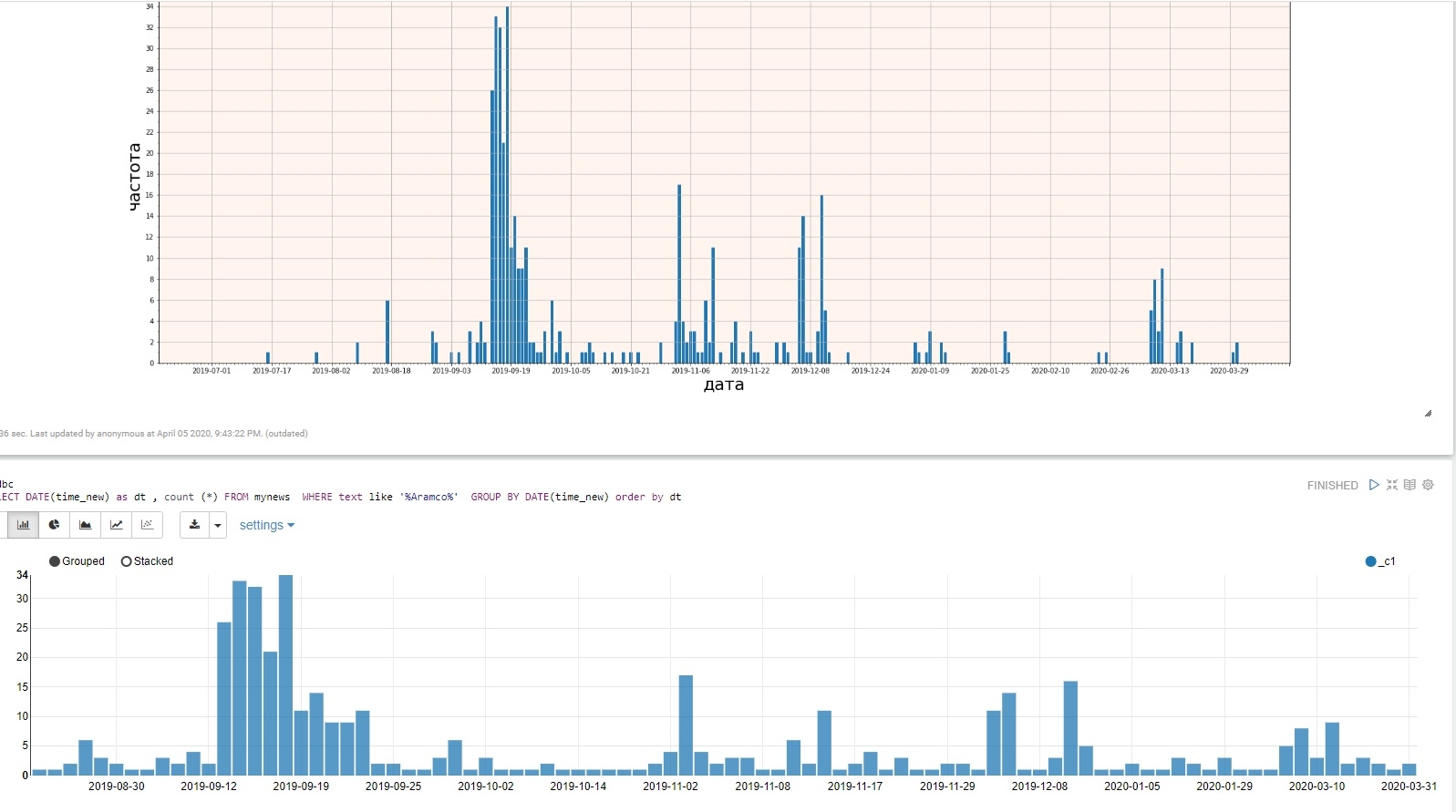
График не такой красивый, но зато более информативный, да и в результате мы имеем два кортежа с датами и соответствующими им частотами. Что делать дальше с этими данными, решать вам.
Если кому-то надо, могу скидывать дампы базы в CSV-формате на яндекс диск или сюда, кому надо это, пишите в группу Вконтакте
Комментарии
Комментировать могуть только зарегистрированные пользователи