
Оглавление:
1. Что такое Apache HBase.
2. Установка и настройка Apache HBase.
3. Работа с базами Apache HBase.
4. Загрузка данных из файлов в таблицу Apache HBase.
5. Фильтрация данных таблиц Apache HBase (команда scan).
6. SQL-запросы к Apache HBase (посредством импорта в Hive).
Что такое Apache HBase.
Apache HBase - это нереляционная база данных Hadoop, распределенное, масштабируемое, хранилище больших данных. В качестве файловой системы для хранения "сырых данных" используется распределенная файловая система HDFS, формат хранения - HFile. Для совершения процедур преобразования данных применяется парадигма (хорошее слово, когда до конца не разобрался, что это) MapReduce.
Главный плюс Apache HBase - возможность хранения данных любого типа, особо не заморачиваясь структурой базы. Для часто изменяющихся данных не надо создавать отдельную таблицу, так как существует версионность колонок, но об этом попозже. Также пустые ячейки не занимают память на диске, что так же немаловажно.
Один из минусов - отсутствие возможности взаимодействия с данными посредством SQL-запросов, однако можно сделать "снимок" базы, экспортировать его в Hive или Phoenix, и осуществлять запросы к данным.
Это был поток сознания, который попытаемся отформатировать на практике далее, приступим!
Установка и настройка Apache HBase.
Просто так HBase установить не удастся, для этого сначала нужно установить Hadoop (HDFS, MapReduce) и Zookeeper. Не хочу тратить время на варианты установки Standalone и Pseudo-distributed, так как они гораздо проще и не нужны в проде. Поэтому сразу займемся распределенной конфигурацией с одним мастером и двумя подчиненными (RegionServer в терминологии HBase) узлами. Поэтому сначала настраиваем кластер HADOOP и распределенный кворум Zookeeper.
После этого можно приступить к установке HBase. Если вы уже установили Hadoop и Zookeeper, то первые шаги не вызовут никаких затруднений, они стандартны. Стоит отметить, что Hadoop должен быть уже запущен, так как нам понадобится создавать каталоги в HDFS.
Установка:
1. Скачать требуемую версию с официального сайта.
Я рискнул и скачал последнюю стабильную версию на данный момент времени 2.2.6.
2. Распаковать содержимое архива в каталог /usr/local/hbase-2.2.6 (может быть и другой). Назначить владельцем данного каталога пользователя hduser (данного пользователя мы создали ранее для всей экосистемы. У вас может быть другой, например hbase).
3. Создать каталог /usr/local/hbase-2.2.6/tmp.
4. Cоздать в корне HDFS каталог HBase, примеры команд hdfs приведены ЗДЕСЬ.
Владельцем каталога должен быть ваш пользователь (в моем случае hduser).
5. Редактируем файл настроек hbase-env.sh в каталоге /usr/local/hbase-2.2.6/conf.
Раскомментировать и указать следующие значения:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 - путь к каталогу установки JDK. У вас может отличаться.
export HBASE_MANAGES_ZK=true - указываем, что будем использовать встроенный в HBase Zookeeper. После долгих экспериментов пришел к выводу, что данная настройка актуальна для однонодовой сборки и псевдораспределенной. Для распределенной, о ней пойдет речь дальше, я установил параметр в false.
6. Редактируем файл настроек hbase-site.xml в каталоге /usr/local/hbase-2.2.6/conf.
Мои настройки в данном файле представлены на скриншоте ниже:
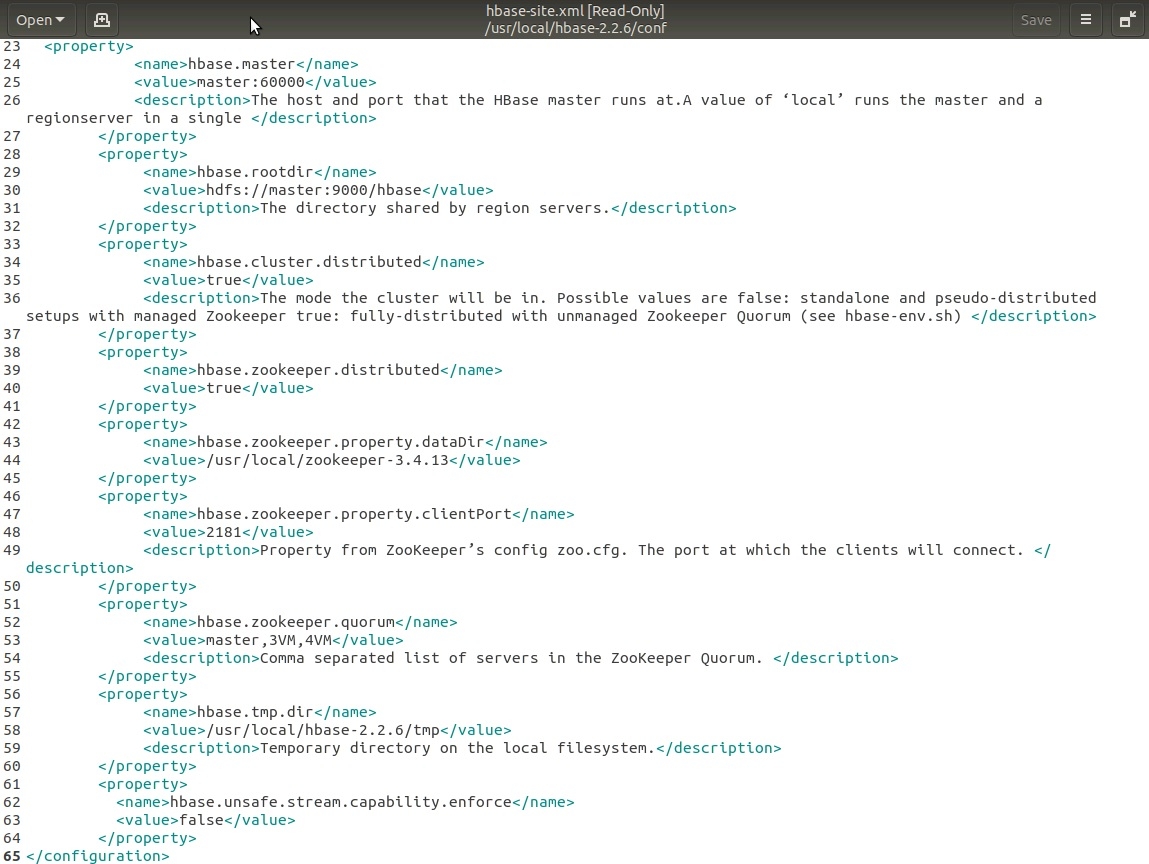
.
Все свойства я думаю понятны, если вы знаете английский язык, но это минимально необходимое количество, в реальности их гораздо больше. Описание некоторых из них:
hbase.master - значение master:60000 - имя (может быть IP-адрес) и порт машины-мастера
hbase.rootdir - значение hdfs://master:9000/hbase - путь к каталогу hbase, который мы создали на шаге 4. Порт hdfs указывается в настройках hdfs файл core-site.xml.
hbase.zookeeper.quorum - здесь необходимо перечислить все адреса Zookeeper-серверов.
Остальные настройки я думаю не нуждаются в пояснениях.
7. Редактируем файл настроек regionservers (если он не существует, то создать) в каталоге /usr/local/hbase-2.2.6/conf.
В данном файле указать с новой строки все будущие починенные машины, или regionservers.
У меня так:
3VM
4VM
8. Настраиваем regionservers:
Копируем каталог hbase-2.2.6 на все будущие подчиненные regionservers. Например, с помощью SCP (sudo scp -r hduser@Master:/usr/local/hbase-2.2.6/* hduser@3VM:/usr/local/hbase-2.2.6/).
Редактируем на каждом regionserver файл настроек hbase-site.xml в каталоге /usr/local/hbase-2.2.6/conf.
В данном случае достаточно просто удалить ненужные настройки в редакторе. Настройки представлены на скриншоте ниже:

9. Запускаем и проверяем работоспособность кластера.
Запуск HBase:
Перейти в каталог /usr/local/hbase-2.2.6/bin
Запустить скрипт: ./hbase-start.sh
При удачном запуске:
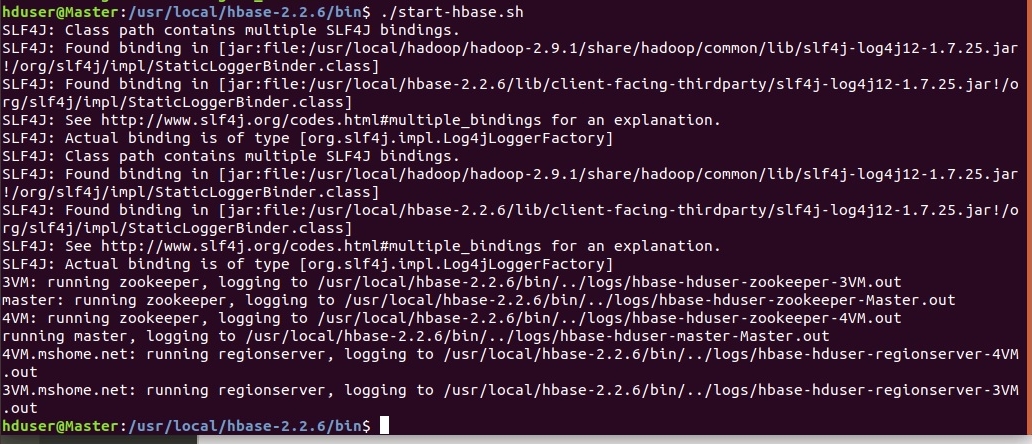
Обратите внимание, что Zookeeper и regionservers запускаются автоматически (при заранее настроенном SSH).
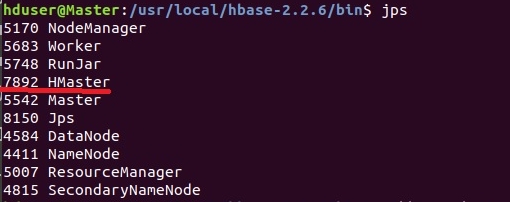
Посмотрим java-процессы.
На мастере:
На regionservers:
Здесь важен процесс HMaster
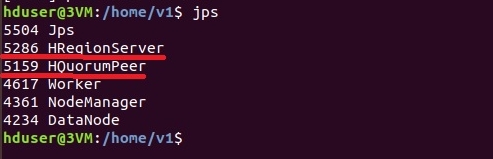
А здесь HRegionServer и HQuorumPeer
Теперь запустим шелл HBase и проверим работоспособность.
Запуск шелл:
./hbase shell
Шелл-команда для отображения списка таблиц list
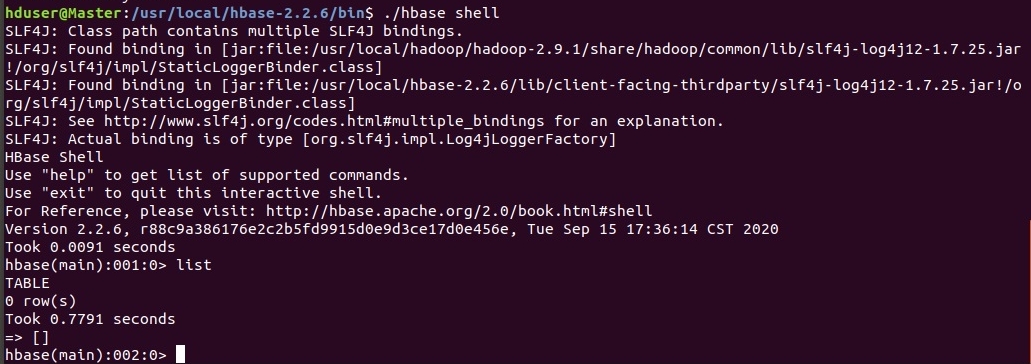
Остановить кластер: ./stop-hbase.sh
Состояние кластера также можно посмотреть в веб-интерфейсе кластера, порт 16010:
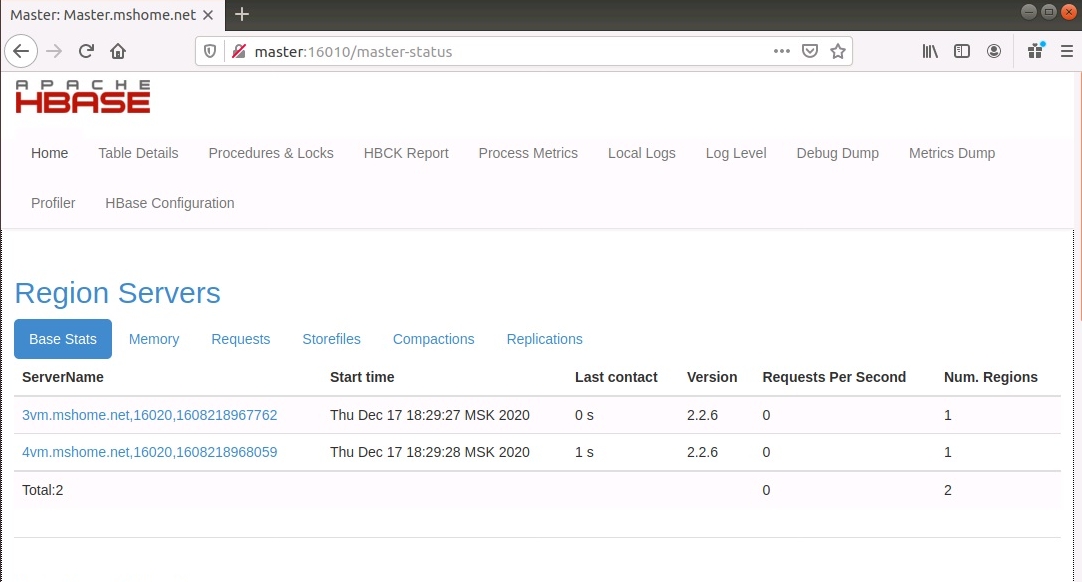
Вот и все, кластер настроен, пора разбираться с самым интересным - со структурой таблиц!
Работа с базами Apache HBase.
Изначально структуру таблиц HBase можно рассматривать как обычные табличные данные. Первая отличительная особенность - пустые ячейки не сохраняются на диске (коряво написал, поправьте, если что). Вторая особенность - данные ячеек при добавлении новых данных не удаляются, а остаются как более ранняя версия. Каждому значению ячейки сопоставляется временная метка. Третья особенность - нет типов данных, грузи в ячейку, что хочешь.
Приступим к структуре таблиц:
RowKey - уникальный идентификатор записи (строки), идентично таблицам в RDMS.
ColumnFamily - семейство колонок, объединяет несколько столбцов, которые схожи по типу данных
Создание таблиц HBase:
Полный формат команды: create 'имя_таблицы', {NAME => 'семейство_колонок1'}, {NAME => 'семейство_колонок2'}
Краткий формат команды: create 'имя_таблицы','семейство_колонок', семейств колонок можно создать сразу несколько (create 'имя_таблицы','семейство_колонок1', 'семейство_колонок2').
На примере ниже создаем таблицу test с семейством колонок data.
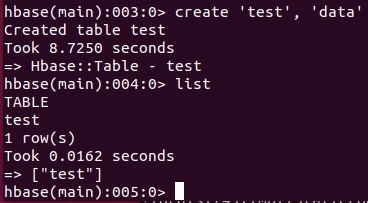
Удаление таблиц HBase:
Сначала таблицу нужно отключить командой disable 'имя_таблицы'
И удалить: drop 'имя_таблицы'
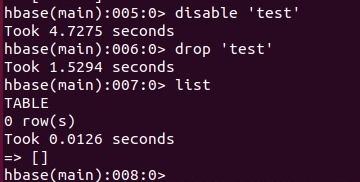
Создадим таблицу test с семейством колонок data заново.
Команда describe 'имя_таблицы' позволяет получить список параметров таблицы:
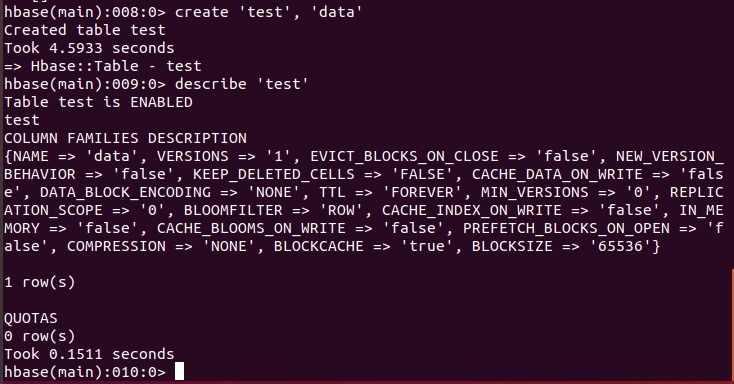
Назначение и изменение некоторых параметров мы рассмотрим далее.
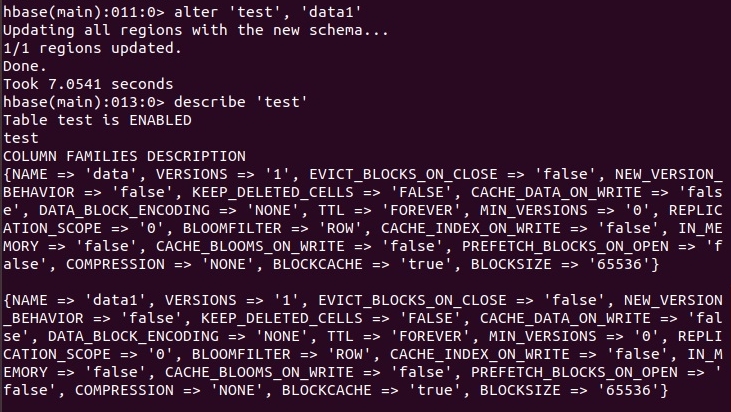
Команда alter позволяет вносить изменения в структуру существующей таблицы, имеет полный и краткий формат.
alter 'test', 'data1' - добавить новое семейство колонок data1, в кратком виде.
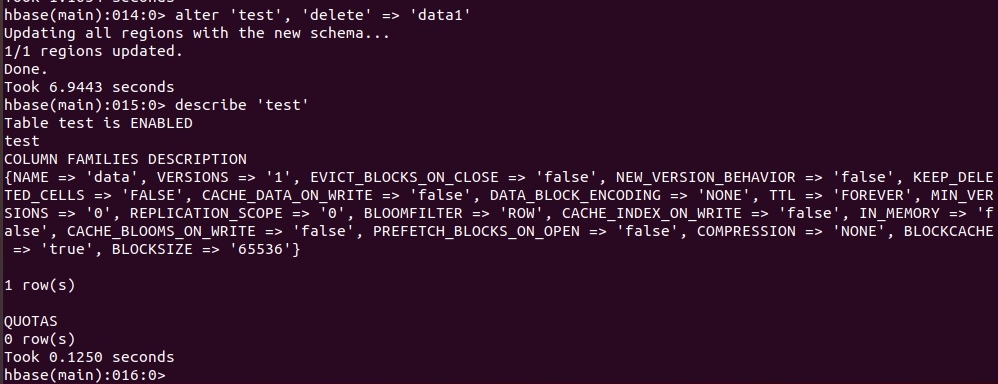
Удаление семейства колонок с помощью команды alter:
Полная запись: alter 'test', {NAME => 'data1', METHOD => delete }
Краткая запись: alter 'test', 'delete' => 'data1'
Добавление данных в таблицу HBase:
Формат команды вставки: put 'имя_таблицы','ключ','семейство_колонок:колонка','значение','метка_времени'
ключ - уникальное значение (RowKey)
колонка - может быть несколько, создаётся динамически, если не существует.
метка_времени - или timestamp, необязательный параметр, время занесения данных в базу, генерируется автоматически.
Пример:put 'test','id_12345','data:name','John'
С помощью команды scan можно посмотреть данные в таблице
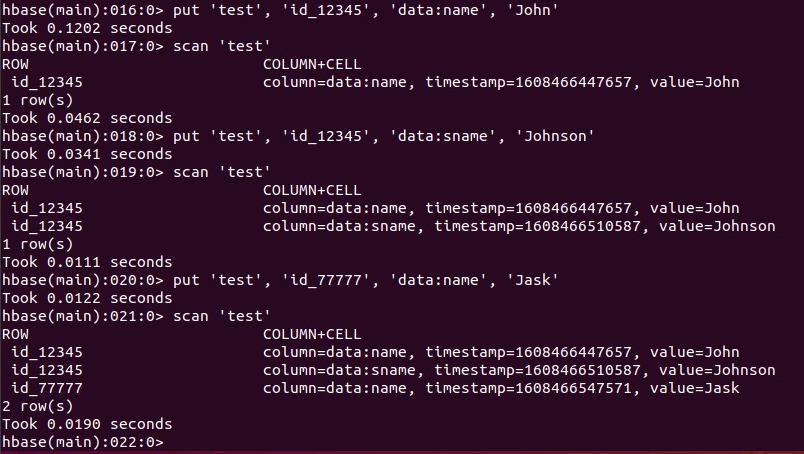
Создадим еще одну колонку в семействе data:
put 'test','id_12345','data:sname','Johnson'
Создадим еще одну запись:
put 'test','id_77777','data:name','Joe'
Теперь посмотрите свойства таблицы с помощью команды describe и обратите внимание на свойство VERSIONS, которое по умолчанию равно единице. Изменим значение этого свойства для семейства колонок data с помощью команды alter:
alter 'test', NAME=>'data', VERSIONS=>3
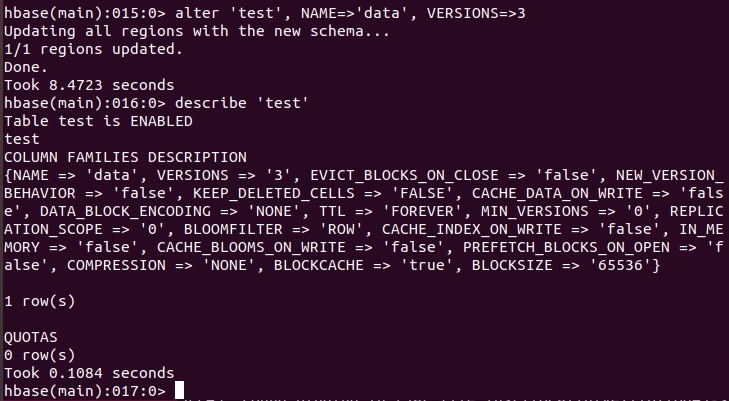
Теперь внесите новое значение для записи id_77777 в колонку data:name. Например:
put 'test','id_77777','data:name','Mike'
Посмотрим содержимое таблицы с помощью команды scan и этой же команды, но с учетом версий. Результат смотрим на скриншоте ниже:
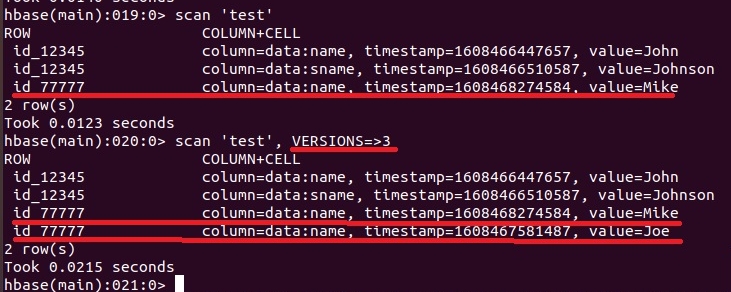
.
Свойство TTL (Time To Live)
Изменим значение данного свойства таблицы с помощью команды alter, установим значение 20 секунд. Синтаксис идентичен предыдущему свойству: alter 'test', NAME=>'data', TTL=>20
Проверим содержимое, и увидим, что все записи стерлись!
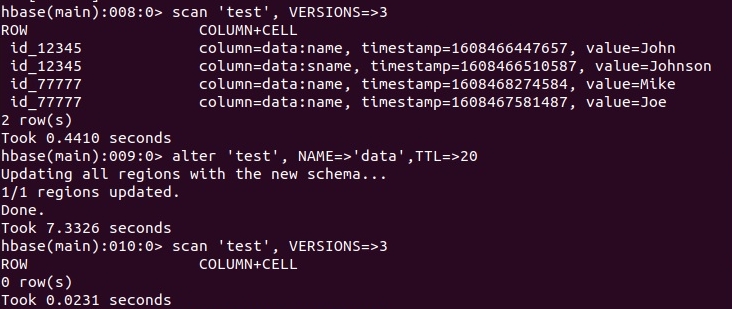
Данное свойство определяет, сколько секунд должно жить значение ячейки от момента создания, даже после команды удаления. В моем случае все данные оказались старее 20-ти секунд от момента создания, поэтому они были удалены.
По умолчанию данное свойство имеет значение 'FOREVER', это видно на скриншотах для команды describe.
Проверим, как работает данное свойство на примере, который представлен на следующем скриншоте.
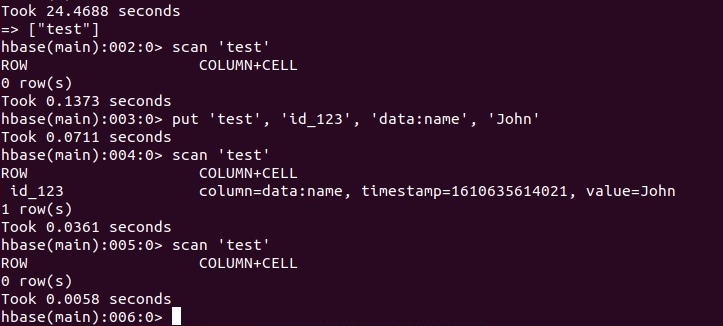
.
Сначала в нашу пустую таблицу запишем новые данные. После этого сразу посмотрим содержимое таблицы с новыми данными. По истечении 20-ти секунд мы видим, что данные удалились.
Удаление данных из таблиц HBase.
Для удаления данных используется команда delete. Формат команды:
delete 'table_name', 'row_key', 'column_name', time_stamp_value
Удаление значения ячейки представлено на скриншоте ниже.
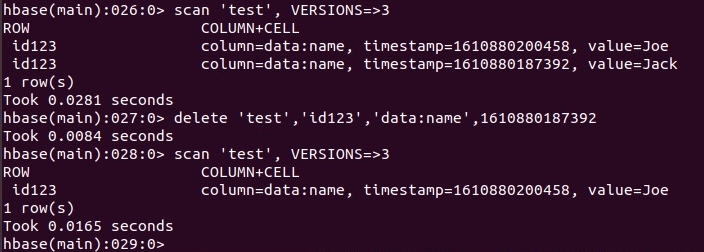
Удалять можно все значения в ячейке, для этого достаточно не указывать time_stamp_value.
Для удаления RowKey используется команда:
deleteall 'table_name', 'row_key'
Удаление таблиц HBase.
Для удаления таблиц и ряда других действий, необходимо "отключить" таблицу командой: disable 'имя_таблицы'
После этого можно удалить таблицу: drop 'имя_таблицы'
Загрузка данных из файлов в таблицу Apache HBase.
Apache HBase позволяет загружать данные в таблицы из внешних файлов различных форматов. Рассмотрим самый популярный текстовый формат хранения CSV.
В качестве примера возьмем нужный датасет с популярного сервиса Kaggle. Так как далее нам необходимо будет описывать тип каждой импортируемой колонки, я взял датасет с малым их количеством. Показался интересным набор оскорбительных твитов Трампа с 2014 по 2021 год. Архив вы можете скачать с НАШЕГО САЙТА
Теперь архив нужно распаковать и скопировать в директорию HDFS (у меня это /input). Команды для работы с HDFS вы можете посмотреть ЗДЕСЬ.
Загруженный файл содержит 5 колонок, первая из них - порядковый номер, что удобно использовать в качестве RowKey.
Теперь создадим таблицу HBase (она должна существовать в момент импорта!) с именем Trump и одним семейством колонок tweet.
create 'Trump', 'tweet'
Все готово для импорта данных, делается это следующей командой (в каталоге bin HBase):
./hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=',' -Dimporttsv.columns='HBASE_ROW_KEY,tweet:tw_date,tweet:target,tweet:insult,tweet:tw' Trump /input/trump_tweets.csv
hbase -встроенная команда
org.apache.hadoop.hbase.mapreduce.ImportTsv - java-класс, реализующий map-reduce задачу импорта
-Dimporttsv.separator - разделитель полей в CSV-файле, в нашем случае это запятая
-Dimporttsv.columns - перечисление колонок в порядке следования, первая - HBASE_ROW_KEY. Не должно быть пробелов!
Trump - имя таблицы в HBase.
/input/trump_tweets.csv - путь к файлу с данными в HDFS.
В результате мы запустим map-reduce задачу импорта, процесс будет отображаться в терминале. В файле встречаются некорректные данные, что привело к некорректной записи данных в таблицу. Но это уже вопросы предобработки исходных данных.
При просмотре данных в таблице командой scan, будет выведено большое количество значений. Поэтому далее рассмотрим фильтры для команды scan.
Фильтрация данных таблиц Apache HBase (команда scan).
Рассмотренная ранее команда scan позволяет производить фильтрацию данных в больших таблицах HBase. Это конечно не SQL, но хотя бы что-то, так мы расплачиваемся за гибкость HBase.
Список доступных фильтров можно получить с помощью команды show_filters:
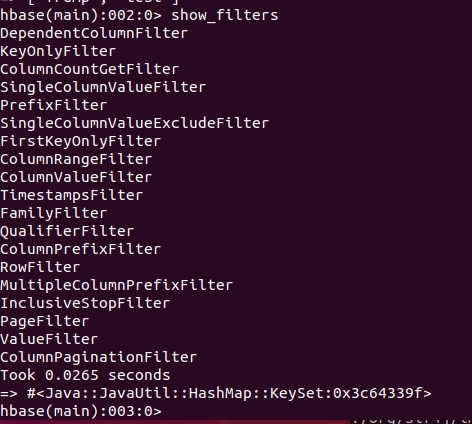
Описание всех фильтров можно найти на официальном сайте Apache HBase.
В общем виде выражение для фильтрации выглядит следующим образом:
scan 'Имя_таблицы', { FILTER => "Название_фильтра ('Параметр')"}
У фильтров может быть один или несколько параметров, перечисляемых через запятую, фигурные скобки необязательны.
Так же несколько фильтров могут объединяться в сложные выражения с помощью скобок и логических операций AND и OR.
Один из простейших фильтров - PrefixFilter, пример команды:
scan 'Trump', { FILTER => "PrefixFilter ('1')"}
В данном случае будут выведены в терминале все значения ключей, у которых RowKey начинается с 1.
Следующий пример:
scan 'Trump', { FILTER => "RowFilter(=, 'substring:11')"}
Результатом выполнения будут все ключи, в которых RowKey содержит подстроку 11. Этот фильтр имеет два параметра: тип сравнения (<, ⇐, =, !=, >, >=) и как сравнивать (в нашем случае substring есть еще binary, binaryprefix, regexstring) с чем (в нашем случае 11).
Пример составного фильтра:
scan 'Trump', { FILTER => "RowFilter(=,'substring:11') OR ValueFilter (=, 'substring:Putin')"}
В результате получим значения всех ключей, в которых RowKey содержит подстроку 11 или значение ячейки, в которой встречается подстрока Putin.
На этом, пожалуй все, более подробное описание всех других фильтров смотрите на официальном сайте. А мы тем временем попробуем все же поэскуэлить (глагол от SQL) над нашими таблицами.
SQL-запросы к Apache HBase (посредством импорта в Hive).
Как мы выяснили ранее, фильтры HBase не обладают тем набором функций, что SQL. Поэтому часто возникает ситуация, когда нужен SQL. Для этого существуют несколько способов: импорт таблиц HBase в Hive, импорт в Phoenix и использование Apache Hue (но это всего лишь веб-оболочка для двух ранее рассмотренных случаев).
В данном разделе будет представлен вариант импорта таблиц HBase в Hive, так как как работать с Hive мы уже разобрались ЗДЕСЬ и ЗДЕСЬ.
С Phoenix и Hue возникло множество проблем, надо разбираться отдельно, если у кого есть опыт установки и настройки, пишите в группу ВКонтакте. Тем более Apache Hue проще ставить в виде doker-образа, но до него пока руки не дошли.
Приступим к импорту в Hive.
Итак, у нас есть таблица в HBase с именем Trump. В ней одно семейство колонок tweet с колонками: tweet:insult,tweet:target,tweet:tw, tweet:date.
Сначала нужно войти в командную строку Hive ($HIVE_HOME/bin hive) и создать внешнюю таблицу командой:
CREATE EXTERNAL TABLE Trump_hive (key string, insult string, target string, tweet string, twdate string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" =":key, tweet:insult, tweet:target, tweet:tw, tweet:tw_date") TBLPROPERTIES ("hbase.table.name"="Trump", "hbase.mapred.output.outputtable" = "Trump");Trump_hive - имя таблицы в Hive
key string, insult string, target string, tweet string, key string, insult string, target string, tweet string, twdate string - имя/тип колонок в Hive. Есть проблемы, с которыми не разобрался, указание иных типов, кроме string привело к NULL в колонках (key должен быть INT а twdate - DATE). Возможно из-за ошибок в файле-источнике.
hbase.columns.mapping - перечень соответствующих импортируемых колонок HBase. Первый - RowKey.
hbase.table.name - имя импортируемой таблицы
hbase.mapred.output.outputtable - имя временной таблицы при импорте, может совпадать с предыдущим именем.
Запускаем задачу, и в случае успеха имеем:
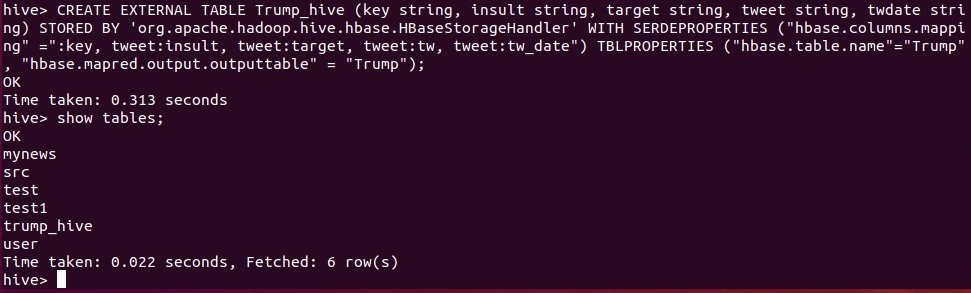
Вот и все, теперь можем делать SQL-запросы к образу таблицы HBase.
Как вы понимаете, в данном случае мы не увидим версионность колонок.
Представленный мной материал составляет не более 5% знаний о HBase, но как говорится: - Дорогу осилит идущий, и эти знания помогут начинающему войти в тему.
Комментарии
Комментировать могуть только зарегистрированные пользователи