
Оглавление:
1. Что такое Spark Stereaming.
2. Создание входных потоков Kafka на Python с использованием Twitter API и VK API.
Что такое Spark Stereaming.
В этой статье мы попытаемся объединить все полученные знания в единую систему. Spark Stereaming - компонент Spark для обработки потоковых данных практически в реальном масштабе времени.
Spark Streaming предоставляет набор программных интерфейсов для потоковой обработки, что позволяет создавать потоковые задания так же, как пакетные задания. Он поддерживает Java, Scala и Python. Spark Streaming автоматически восстанавливает потерянные данные и состояние исполнительного модуля без какого-либо дополнительного кода со стороны разработчика. Spark Streaming позволяет повторно использовать один и тот же код для пакетной обработки, объединять потоки с данными или выполнять специальные запросы по состоянию потока.
Spark Streaming может считывать данные из HDFS , Flume , Kafka , Twitter и ZeroMQ. Можно определить свои собственные источники данных. Spark Streaming может запускаться в режиме автономного кластера Spark или в других поддерживаемых диспетчерах ресурсов кластера. Он также включает режим локального запуска для разработки. В производственной среде Spark Streaming использует ZooKeeper и HDFS для обеспечения высокой доступности.
Создание входных потоков Kafka на Python с использованием Twitter API и VK API.
Для создания входных потоков будем использовать модный нынче язык программирования Python. Получать данные будем через API социальных сетей, хотя их возможности в буржуйских сетях на данный момент сильно урезаются, а в Twitter для новых аккаунтов просто недоступны. Альтернативой может быть парсинг веб-страниц, но это требует большего количества времени на разработку, и не об этом сейчас речь.
Начнем с Twitter.
Первый этап взаимодействия с любыми API социальных сетей - аутентификация. Для этого нам нужно зарегистрировать в данной сети свое приложение, и получить для него ключи безопасности и токены. В Twitter их аж 4 штуки: consumer_key, consumer_secret, access_token, access_token_secret. Данные ключи доступны по следующей ссылке в разделе Keys and tokens.
Теперь про Python, для взаимодействия с Twitter API я использовал библиотеку tweepy.
Код аутентификации выглядит следующим образом:
from tweepy import OAuthHandler
from tweepy import API
consumer_key = "XXXXXXXXXXXXXXXXXXXx"
consumer_secret = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
try:
auth = OAuthHandler(consumer_key, consumer_secret)
except:
print ('!!!!!')
access_token = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
access_token_secret = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
auth.set_access_token(access_token, access_token_secret)
api = API(auth)
Все, мы авторизовались, теперь можем отправлять запросы к социальной сети. Параметры запроса:
keywords_to_track = [u'Russia'] - отбирать твиты со словом Russia в кодировке юникод.
myStream.filter(track = keywords_to_track, languages=['en'])- язык английский.
В потоке (класс MyStreamListener) определяем брокер kafka, у меня он bootstrap_servers=['172.20.161.141:9094']. master.mshome.net как на скриншоте, более удобно.
Далее указываем тему my_topic = 'Twitter', парсим полученный json и отправляем в Kafka.
Скриншот скрипта представлен ниже.
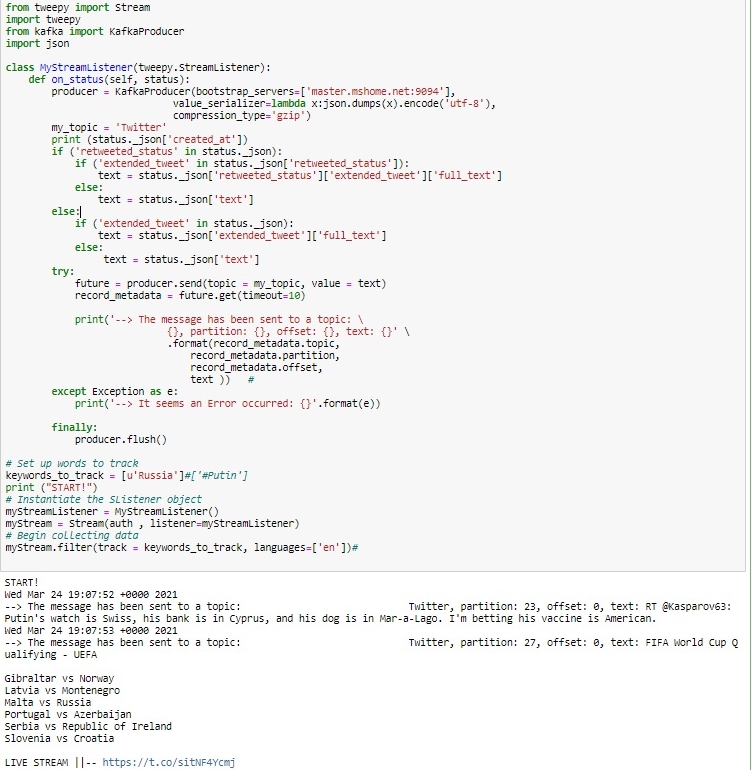
Скрипт коротенький, поэтому еще что-то пояснять не вижу смысла.
Теперь поработаем с VK.
Комментарии
Комментировать могуть только зарегистрированные пользователи