
Оглавление:
1. Алгоритм классификации текстов NaiveBayes в Spark.
2. NaiveBayes в Spark MLlib
3. NaiveBayes в Spark ML
4. LogisticRegression (Логистическая регрессия) в Spark ML
1. Алгоритм классификации текстов NaiveBayes в Spark.
Apache Spark включает в себя несколько прикладных пакетов, среди которых особое место занимают библиотека MLlib (spark.mllib) и ML(spark.ml). MLib разработана в 2014 году и ориентирована на работу с плохо структурированными данными на основе RDD.
ML разработана в 2016 году и основное ее отличие - ориентированность на более удобный структурированный тип данных - DataFrame. Также в данной библиотеке реализован новый механизм обработки данных - контейнеры (pipelines), который значительно упрощает реализацию процедур преобразования данных.
В данном разделе представлен алгоритм NaiveBayes для обеих библиотек.
Реализация на языке Python (PySpark) в блокноте Apache Zeppelin.
Важно! библиотека MLlib требует наличия NumPy на всех нодах кластера, поэтому установите данный пакет.
В примере будем использовать классический пример классификации почтовых сообщений на СПАМ и НЕ СПАМ. Для этого необходимо скачать тестовую выборку SMSSpamCollection, ссылку давать не буду, ее просто нагуглить.
Набор представляет из себя текстовый файл, в котором содержатся почтовые сообщения, разделенные переводом строки /n. Метка класса в строке отделена от сообщения символом табуляции /t.
Тестовый набор необходимо загрузить в HDFS, но не обязательно, можно загрузить и из локальной файловой системы.
Теперь можно приступать.
2. NaiveBayes в Spark MLlib.
Начинаем с алгоритма NaiveBayes, так как он самый простой для понимания, и имеет хорошие характеристики при обработке коротких сообщений и скорости обучения и принятия решений. Суть алгоритма проста: на этапе обучения считаем частоты (вероятности) встречаемости слов для каждого класса, после чего при классификации данные частоты суммируются для слов из нового сообщения.
Импортируем необходимые библиотеки:
from pyspark import SparkContext
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.classification import NaiveBayes
from pyspark.mllib.feature import HashingTF
Получим Spark Context и создадим RDD из набора данных:
sc = SparkContext.getOrCreate()
inputRdd = sc.textFile("hdfs://Master:9000//input/smsspamcollection/SMSSpamCollection")
Посмотрим содержимое первых десяти записей:
for line in inputRdd.take(10):
print (line)
Фильтруем только сообщения класса spam в новый RDD:
spamRDD1 = inputRdd.filter(lambda x: x.split("\t")[0] == 'spam')
И оставим только сообщения без меток:
spam = spamRDD1.map(lambda x : x.split("\t")[1])
Такие же процедуры проделаем и с сообщениями не спам. Код не привожу, он идентичен.
Настроим модуль преобразования сообщений в вектор:
tf = HashingTF(numFeatures = 8000)
Здесь 8000 - количество признаков, или объем словаря. В примере представлено наилучшее значение для выборки, с которой работаем. Этот параметр можно менять и смотреть, как меняется качество классификации.
Далее преобразуем оба набора в векторы признаков, предварительно разбив на слова через пробел:
spamFeatures = spam.map(lambda msg: tf.transform(msg.split(" ")))
Та же процедура и для набора сообщений не спам.
Далее проставим метки, 1 - для спама и 0 - для не спама соответственно:
positiveExamples = spamFeatures.map(lambda features: LabeledPoint(1, features))
Снова объединим наборы уже с метками и векторами признаков (получение negativeExamples на предыдущих шагах пропущено, чтобы вы подумали):
training_data = positiveExamples.union(negativeExamples)
Разбиваем выборку на обучающую и тестовую:
trainset, testset = training_data.randomSplit([0.6, 0.4])
Обучаем модель:
model = NaiveBayes.train(trainset, 1.0)
По умолчанию используется модель multinomial, где каждому признаку соответствует частота встречаемости в документе, в другом варианте (bernoulli) каждому признаку соответствует значение 1, если он присутствует в документе, и 0 - если нет.
Проверим модель и посчитаем точность:
predictionLabel = testset.map(lambda x: (model.predict(x.features), x.label))
accuracy = predictionLabel.filter(lambda x : x[0]==x[1]).count()/testset.count()
print ("Model accuracy : {:.2f}".format(accuracy))
Точность неплохая:
Model accuracy : 0.97
Теперь создадим RDD с классифицируемыми сообщениями:
testRDD = sc.parallelize(["WINNER!! As a valued network customer you have been selected to receivea £900 prize reward! To claim call 09061701461. Claim code KL341. Valid 12 hours only.", \
"07732584351 - Rodger Burns - MSG = We tried to call you re your reply to our sms for a free nokia mobile + free camcorder. Please call now 08000930705 for delivery tomorrow", \
"Get me your passport", \
"Thanks for your subscription to Ringtone UK your mobile will be charged £5/month Please confirm by replying YES or NO. If you reply NO you will not be charged", \
"i am ill cant work tomorrow", \
"Congrats! 1 year special cinema pass for 2 is yours. call 09061209465 now!"
])
Преобразуем его в вектор и отдадим модели на классификацию:
testFeatures = testRDD.map(lambda msg: tf.transform(msg.split(" ")))
res = model.predict(testFeatures)
for line in res.collect():
print (line)
Модель выдает метки классов для новых сообщений:
1.0
1.0
0.0
1.0
0.0
1.0
3. NaiveBayes в Spark ML.
Для работы с библиотекой ML необходимо иметь знания о структуре данных DataFrame. Данные этого типа колоночно-структурированы, что обеспечивает взаимодействие с ними посредством SparkSQL.
Приступим, загрузим необходимые зависимости:
from pyspark.sql import SparkSession
from pyspark.ml.feature import CountVectorizer
from pyspark.ml.feature import RegexTokenizer
from pyspark.ml.feature import StringIndexer
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.classification import NaiveBayes, NaiveBayesModel
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.sql.functions import monotonically_increasing_id
from pyspark.sql.functions import desc
Создадим Spark-сессию:
spark = SparkSession.builder.appName('SpamClassifier').getOrCreate()
Считаем данные из HDFS в DataFrame:
df = spark.read.option("header", "false") \
.option("delimiter", "\t") \
.option("inferSchema", "true") \
.csv("hdfs://Master:9000//input/smsspamcollection/SMSSpamCollection") \
.withColumnRenamed("_c0", "label_string") \
.withColumnRenamed("_c1", "sms")
Краткое описание:
1. Заголовок не нужен, создадим сами(имена колонок будут _c0 и _c1).
2. Разделитель колонок - табуляция (\t)
3. inferSchema - самостоятельно определить типы данных
4. Путь к файлу.
5. Переименовать колонки
Посмотрим на наши данные:
df.show()
Создадим этапы конвейерной обработки данных. Инициализируем как список:
stages = []
Создадим первый этап - очистка сообщений из колонки sms с помощью регулярного выражения. Останутся только слова, идущие через пробел, результат будет помещен в новую колонку tokens. Затем добавим его в список этапов конвейера.
regexTokenizer = RegexTokenizer(inputCol="sms", outputCol="tokens", pattern="\\W+")
stages += [regexTokenizer]
Далее посчитаем встречаемость слов из колонки tokens с помощью CountVectorizer и поместим полученный размер словаря и значения признаков в колонку token_features.
cv = CountVectorizer(inputCol="tokens", outputCol="token_features")
stages += [cv]
Преобразуем метки классов из колонки label_string в числовые значения и запишем в новую колонку label:
indexer = StringIndexer(inputCol="label_string", outputCol="label")
stages += [indexer]
Преобразуем наборы признаков из колонки token_features в общий вектор и поместим в колонку features:
vecAssembler = VectorAssembler(inputCols=['token_features'], outputCol="features")
stages += [vecAssembler]
На этом этапы преобразования данных для конвейера готовы, создадим сам конвейер:
pipeline = Pipeline(stages=stages)
Теперь преобразуем наши данные и создадим новый датафрейм:
data = pipeline.fit(df).transform(df)
Разобьём выборку на обучающую и тестовую:
train, test = data.randomSplit([0.7, 0.3], seed = 2018)
Инициализируем и обучим модель:
nb = NaiveBayes(smoothing=1.0, modelType="multinomial")
model = nb.fit(train)
smoothing - параметр сглаживания, с его помощью мы уходим от нулевых вероятностей слов, которые не встречались в обучающей выборке. В данном случае, ко всем вероятностям добавляем единицу, даже если мы это слово не встречали.
modelType - "bernoulli" или "multinomial".
Далее сохраним модель в файловой системе, и загрузим ее снова:
model.write().overwrite().save("hdfs://Master:9000//input/1")
sameModel = NaiveBayesModel.load("hdfs://Master:9000//input/1")
Теперь оценим качество модели, подробно описывать не буду, вроде и так все понятно:
predictions.select("label", "prediction", "probability").show()
evaluator = BinaryClassificationEvaluator(rawPredictionCol="prediction")
accuracy = evaluator.evaluate(predictions)
print ("Model Accuracy: ", accuracy)
Точность модели:
Model Accuracy: 0.9490726020137785
Теперь можно приступать к классификации новых сообщений. Но данном моменте случился глобальный затуп, так как про датафреймы я еще не прочитал книгу, а нагуглить влоб не получалось.
Поэтому привожу далее костыли, которые (если повезет) мне помогут специалисты в нашей группе Вконтакте
Приступим: создаем датафрейм с такой же структурой, что и обучающая выборка. Колонки label_string и sms. Метки ставим от балды, но я поставил правильные, чтобы лучше видеть ошибки.
df1 = spark.createDataFrame([("spam", "FreeMsg Hey there"), \
("ham", "I am waiting"),\
("spam", "URGENT! FreeMsg "),\
( "spam", "WINNER! Had your mobile "),\
( "ham", "I am going to school"), \
( "ham", "I love you")],\
["label_string", "sms"])
Теперь то самое страшное место, с которым пришлось повозиться. CountVectorizer в результате преобразования возвращает размер словаря, или счетчик все слов, которые встретились хотя бы один раз. Поэтому нашу новую выборку напрямую отдавать нельзя, так как размер словаря будет очень маленьким. Поэтому необходимо объединить обучающий датафрейм и вновь созданный. Также следует отметить, что если в новой выборке встретится слово, которое не встречалось в обучающей.
Объединяем:
df2 = df.union(df1)
Преобразуем данные:
data1 = pipeline.fit(df2).transform(df2)
Теперь нарисовалась вторая проблема, которую решил быстро в лоб, но уверен, есть более красивое решение. Наши классифицируемые признаки лежат в самом низу датафрейма (последние 6 строк).
Решение такое: к датафрейму добавим новый столбец index, значения которого простой счетчик строк. После этого отсортируем по убыванию и удалим все, кроме первых шести строк:
df_c = data1.withColumn("index", monotonically_increasing_id())
data1 = df_c.orderBy(desc("index")).drop("index").limit(6)
Классифицируем сообщения и выведем необходимую информацию о предсказанном значении и вероятности:
predictions = sameModel.transform(data1)
predictions.select("label", "prediction", "probability").show()
Решение вышеозначенных проблем
Все проблемы легко решаются заменой CountVectorizer на HashingTF на этапе создания конвейера обработки. Достаточно импортировать функцию HashingTF заменить строку:
Импортируем from pyspark.ml.feature import HashingTF
Заменяем cv = CountVectorizer(inputCol="tokens", outputCol="token_features")
на:cv = HashingTF(inputCol="tokens", outputCol="token_features", numFeatures=8000)
После этого достаточно преобразовать новый датафрейм и подать его на обученную модель :
data1 = pipeline.fit(df1).transform(df1)
data1 = sameModel.transform(data1)
data1.select("label","sms", "prediction", "probability").show()
Точность модели можно повысить (я проверил, до 0,96), если добавить в конвейер преобразования функцию удаления слов StopWordsRemover и увеличить размер признаков до 9000.
Но это я уже описывать не буду, попробуйте сделать сами, все вопросы через группу ВКонтакте.
4. LogisticRegression (Логистическая регрессия) в Spark ML.
Логистическая регрессия - это разновидность Байесовского классификатора, позволяющая оценить вероятность отнесения элемента выборки к классу.
Применение данной модели практически не отличается от ранее рассмотренного, необходимо только импортировать модель, и обучить с необходимыми параметрами.
Импорт:
from pyspark.ml.classification import LogisticRegression
Обучение:
lr = LogisticRegression(maxIter=100, regParam=0.001, elasticNetParam=0.1)
lrModel = lr.fit(train)
maxIter - максимальное количество итераций для запуска алгоритма оптимизации.
regParam - параметр регуляризации (смотрите формулы), соответствует параметру лямбда, значение больше или равно нулю.
elasticNetParam - параметр регуляризации, соответствует альфа, от 0 до 1 [0,1].
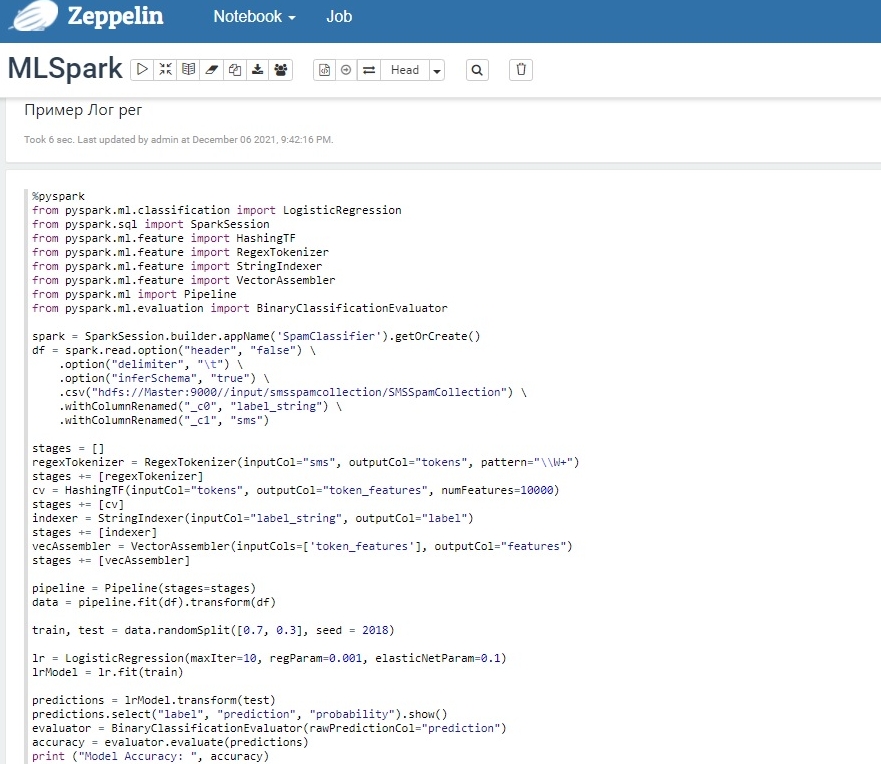
Полный код скрипта представлен на скриншоте, так как вроде описывать больше нечего, хотя есть еще множество параметров модели, они менее важны, чем представленные.
Комментарии
Комментировать могуть только зарегистрированные пользователи
В данном разделе очень нужна помощь специалистов! Хотелось бы увидеть отклик ВКонтакте (https://vk.com/club183865663).