Введение.
Вот уже год занимаюсь исследованием экосистемы (не побоюсь этого слова) HADOOP. Когда накопились определенные знания, решил поделиться ими с миром, так как информации в русском сегменте Интернет не так уж и много.
Итак, HADOOP - это свободно распространяемый фреймворк, разработанный Apache Software Foundation. Представляет собой набор программных средств для распределенного хранения и обработки массивов данных большого объема (BigData). Термин "Большие данные"(BigData) не имеет в данный момент четкого определения, так как для кого-то 10Гб много, а для кого-то и 100 Тб не очень. Но для себя я лично понял, что HADOOP следует применять тогда, когда классические методы обработки информации становятся неприменимы. Например, когда простые запросы к вашей SQL базе данных начинают выполняться часами. Так же HADOOP выигрывает тогда, когда у вас есть много устаревшего железа, а денег на новое и быстрое железо не хватает, да и за сам фреймворк платить не надо.
В естественной среде обитания компоненты HADOOP устанавливаются на ОС семейства Linux с серверным железом, десятками гигабайт оперативной памяти (как минимум) и терабайтными винтами. Такие конфигурации мы рассматривать не будем, так как в этом случае нам нужно много денег и крутой сисадмин. Для того, чтобы понять что такое HADOOP, как он работает и какие его компоненты нам нужны, будет достаточно настольного ПК. Минимальные требования к железу: процессор - 2 ядра по 2Ггц, оперативная память - 8 Гб, жесткий диск на 100 Гб.С точки зрения железа тут наиболее критична оперативная память, так как кластер из трех машин гарантированно сожрет 6Гб оперативки. В статье будет рассмотрен 3-х нодовый кластер (3 ПК) поэтому данные требования для такой конфигурации. Просто если система распределенная, то мне интересно экспериментировать с системой, максимально приближенной к реальности. Если же вам эти параметры по железу недоступны, можно изучать HADOOP и на однонодовом кластере, тут вам понадобиться всего лишь процессор с одним ядром, 4 Гб оперативки и 50 Гб диск.
Операционная система заслуживает отдельного внимания. В нашем примере мы будем разворачивать кластер на виртуальных машинах с ОС Ubuntu 18.04 LTS. Почему так сложно? Да потому что для тех, кто не знаком с Linux, данная ОС будет наиболее приятна на начальном этапе и она встроена в менеджер виртуальных машин Windows 10. В реальных условиях из того, что я видел, большинство кластеров развернуты на CentOS без визуальной оболочки. Так же процесс установки HADOOP был успешно протестирован на Ubuntu 14.04 LTS и 16.04 Server. Навыки работы с командной строкой у вас тоже должны быть, если нет, постараюсь объяснить все доходчиво.
Внимание!!!! Я не хочу никого учить работе в Linux. Сам новичок, если есть что добавить, регистрируйтесь и пишите в комментариях или в группу Вконтакте.
Начальные условия
Итак, у вас есть домашний ПК с как минимум 4Гб оперативки, в нашем примере установлена Windows 10. Если у вас другая ОС, тогда необходимо установить менеджер виртуальных машин, например VMWareWorkstation или VirtualBox. Раньше я пользовался именно этими виртуалками, но Windows 10 меня порадовала наличием встроенного менеджера виртуальных машин Hyper-V.
Включение Hyper-V через раздел "Параметры"
1. Щелкните правой кнопкой мыши кнопку Windows и выберите пункт "Приложения и возможности".
2. Выберите программы и компоненты справа в разделе сопутствующие параметры.
3. Выберите пункт Включение или отключение компонентов Windows.
4. Выберите Hyper-V и нажмите кнопку ОК.
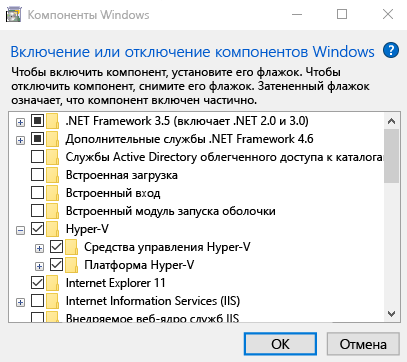
Теперь Hyper-V готово к работе. Для его запуска необходимо кликнуть по иконке поиска и набрать "Hyper", после чего появится приложение, смотри рисунок ниже.
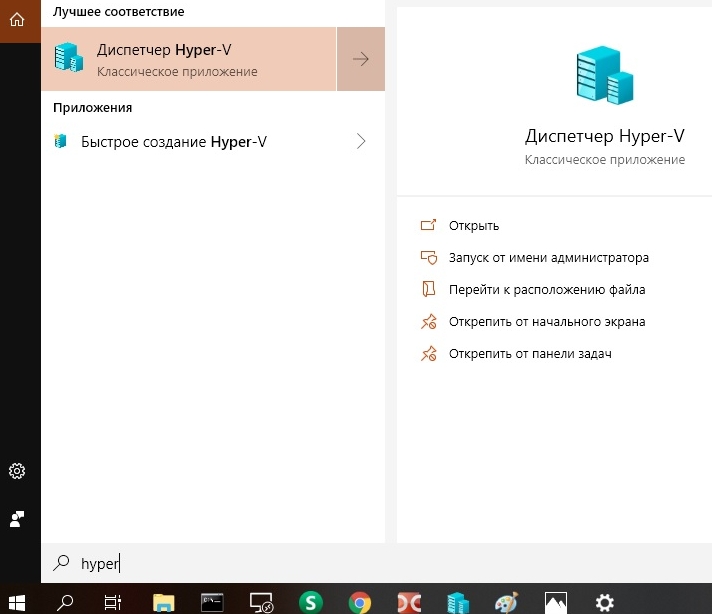
Запускаем диспетчер виртуальных машин Hyper-V, после чего видим главное окно, где в правой части можно увидеть вкладку "Быстро создать". Кликаем по ней, появляется окно выбора операционной системы, выбираем Ubuntu 18, как на рисунке ниже. В ходе установки и настройки системы особо обратить внимание на имя пользователя и пароль.
Это самый простой способ создания виртуальной машины, требующий минимума действий пользователя, в дальнейшем научимся клонировать виртуалки.
Однако данный способ создания виртуальных машин оказался не очень практичен. Настроек по умолчанию не хватает для главной машины кластера, а изменить параметры железа оказалось не такой уж и простой задачей.Так попытка увеличить объем жесткого диска привела к потере виртуалки. После этого я решил создавать виртуалки обычным способом: настройка параметров железа с дальнейшей установкой ОС из образа. Образ Ubuntu 18.04 можно найти ЗДЕСЬ.
Для данного типа установки необходимо в правой панели менеджера Hyper-V выбрать опцию Создать -> Виртуальная машина. Далее указать нужные настройки железа и путь к скачанному образу операционной системы.
Итак, на данном этапе мы имеем: виртуальную машину Ubuntu 18 c визуальным интерфейсом (для облегчения работы для новичков), настроенный сетевой коммутатор, благодаря которому наша виртуалка подключена к отдельной подсети с динамической адресацией и DNS. Также Интернет уже доступен на виртуальной машине. Для начала нужно освоится в ОС Линукс и его визуальным интерфейсом. Для начала нам понадобится встроенный браузер Firefox и менеджер файлов. Следующим этапом будет работа с командной строкой, для вызова которой нажать комбинацию клавиш <Сtrl>+<Аlt>+t. В результате откроется терминал (окно командной строки) в домашнем каталоге текущего пользователя. На рисунке ниже пользователь v1 имя компьютера (hostname) - Master. Каталог, в котором мы сейчас находимся: /home/v1.
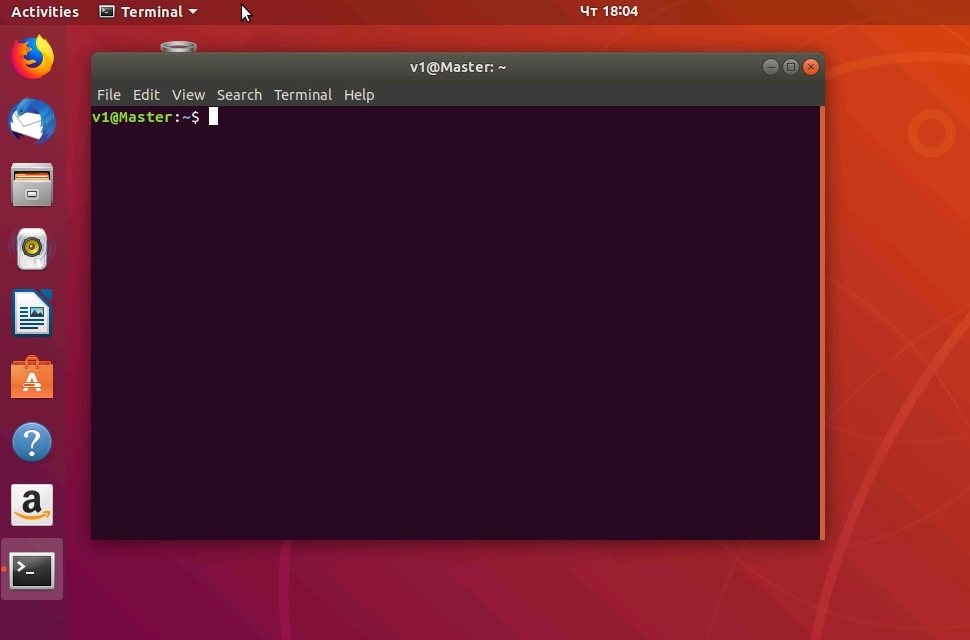
Теперь все готово для настройки операционной системы Ubuntu.
P.S. Вот и прошло 2 года успешного использования виртуалок под Hyper-V. Все шло как по маслу, но в один прекрасный момент все виртуалки перестали загружаться. Смотрим скриншот ниже.
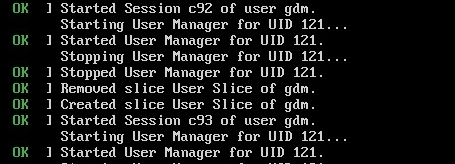
Меня спасло только наличие контрольных точек системы, поэтому - СОЗДАВАЙТЕ КОНТРОЛЬНЫЕ ТОЧКИ!
Решение проблемы:
1. Загрузка из контрольной точки.
2. sudo apt install lightdm
Ставим, со всем соглашаемся, выбираем lightdm, ждем окончания установки.
3. sudo dpkg-reconfigure lightdm
На всякий случай, если что пошло не так.
4. Перезагружаемся!
Настройка операционной системы Ubuntu 18
Для начала нужно установить Java, так как HADOOP является фреймворком, написанном на Яве. Поддерживаются версии Java от 5-й и выше, но как показала практика, наиболее стабильно HADOOP работает с 8-й и 9-й версией.Я предпочел установить версию 8, так как с последней 11-й было много глюков.
Для установки Java (jdk и jre) в терминале выполнить следующие команды:
sudo apt install openjdk-8-jdk-headless
sudo apt install openjdk-8-jre-headless
Правильность установки можно проверить с помощью команды java -version (рисунок ниже)
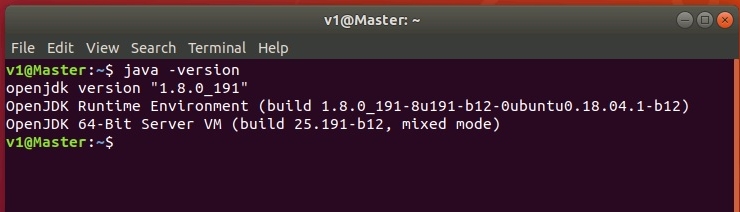
Следует отметить, что возможна установка нескольких версий Java, для выбора активной версии нужно воспользоваться командой sudo update-alternatives --config java
Создание пользователя системы для работы с HADOOP
Тут все очень просто, выполним следующие команды:
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
Создан пользователь hduser в группе hadoop. При создании пользователя важно запомнить пароль, остальные настройки не важны.
Для входа в систему под новым пользователем необходимо ввести команду sudo su hduser, для входа нужно ввести пароль для текущей учетной записи:
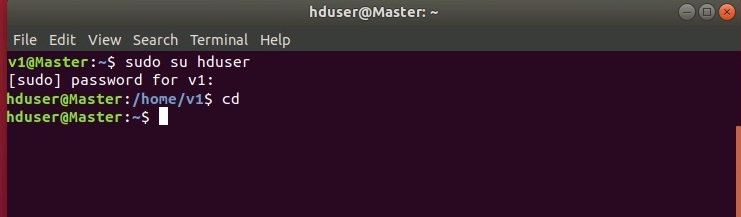
.
Теперь пользователю hduser необходимо добавить права для выполнения команд типа от рута (sudo).
Для этого необходимо сменить текущего пользователя hduser на созданного при установке системы v1 c помощью команды: su v1 и ввести пароль этого пользователя.
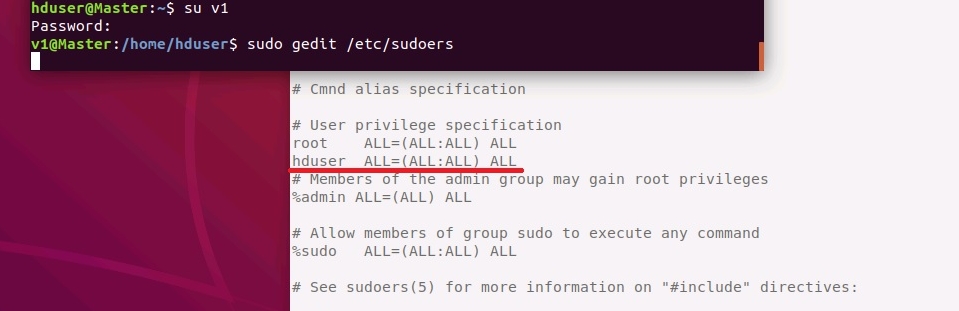
После этого необходимо добавить пользователя hduser в файл /etc/sudoers для чего открыть данный файл в редакторе c помощью команды:
sudo gedit hadoop /etc/sudoers
В текстовом редакторе сразу после пользователя root добавить созданного пользователя hduser, как показано на рисунке ниже.
.
Далее необходимо установить и настроить SSH. Установка SSH-сервера:
sudo apt-get install openssh-server
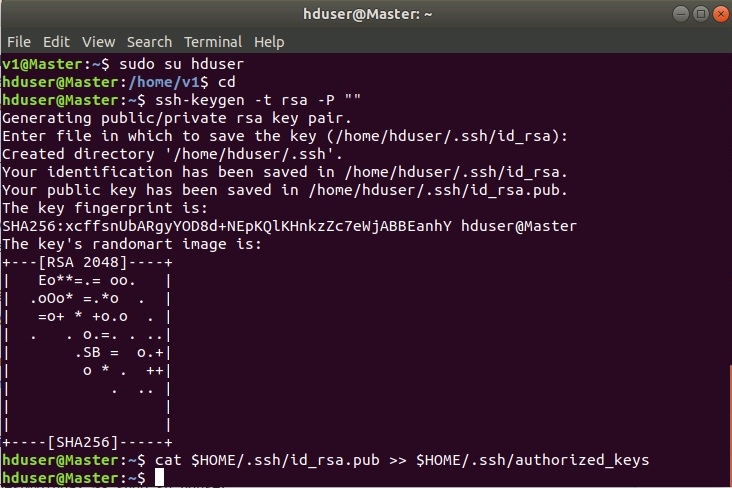
Далее зайти под пользователем hduser и сгенерировать SSH-ключи.
sudo su hduser
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
.
Установка и настройка HADOOP.
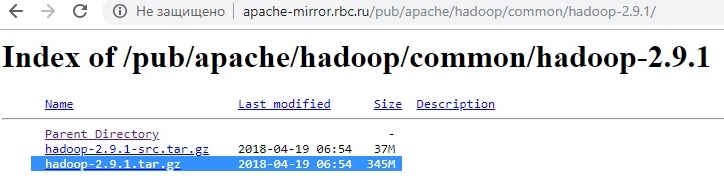
Качаем архив HADOOP ОТСЮДА, я выбрал версию 2.9.1.
.
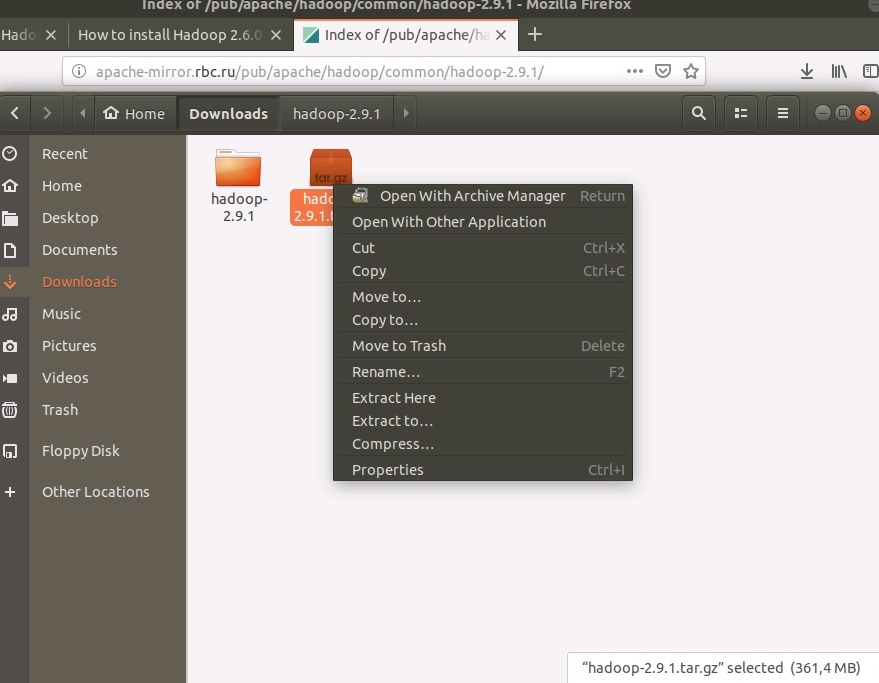
Загрузить архив можно либо через команду wget в консоли, но у нас есть интерфейс и браузер. Поэтому упрощаем себе жизнь и качаем в браузере. Архив загружается в в каталог Downloads текущего пользователя системы. Тут же можно и разархивировать скачанный файл.
.
Для распаковки архива в командной строке нужно выполнить команду sudo tar -xzvf hadoop-2.9.1.tar.gz
Далее необходимо переместить распакованный каталог в рабочий каталог с помощью команды mv, в нашем случае это каталог /usr/local. Следует отметить, что команда mv создаёт несуществующие каталоги, в нашем примере это hadoop/hadoop-2.9.1 :
sudo mv hadoop-2.9.1 /usr/local/hadoop/hadoop-2.9.1
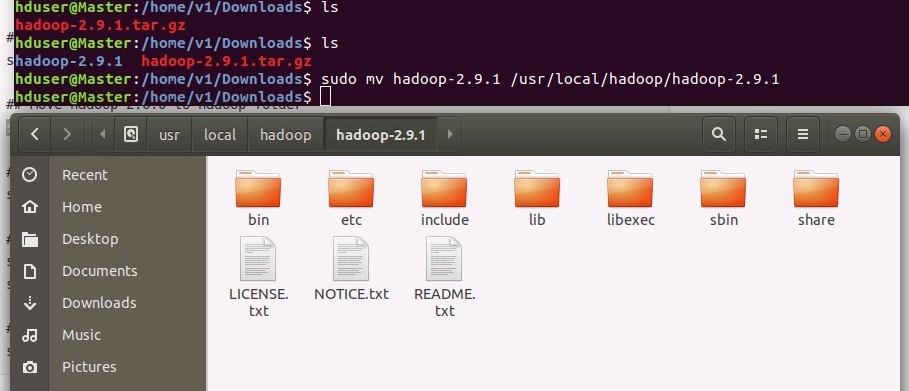
.
Создадим рабочие каталоги для HDFS (NameNode и DataNode) и назначим владельца каталога hadoop (пользователь hduser):
sudo mkdir -p /usr/local/hadoop/hadoop_tmp/hdfs/namenode
sudo mkdir -p /usr/local/hadoop/hadoop_tmp/hdfs/datanode
sudo chown hduser:hadoop -R /usr/local/hadoop/
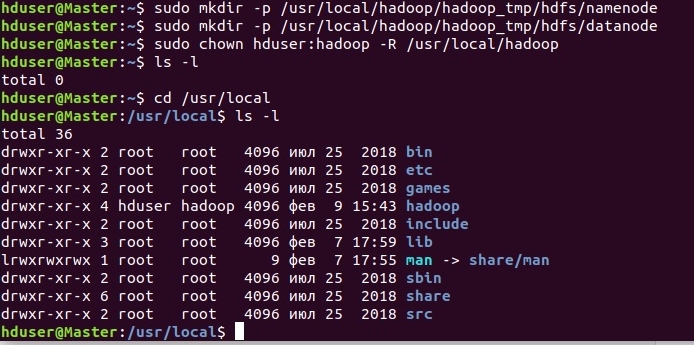
.
Теперь необходимо настроить переменные окружения:
cd
sudo gedit .bashrc
В текстовом редакторе в конец файла вставить следующие строки:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.1
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
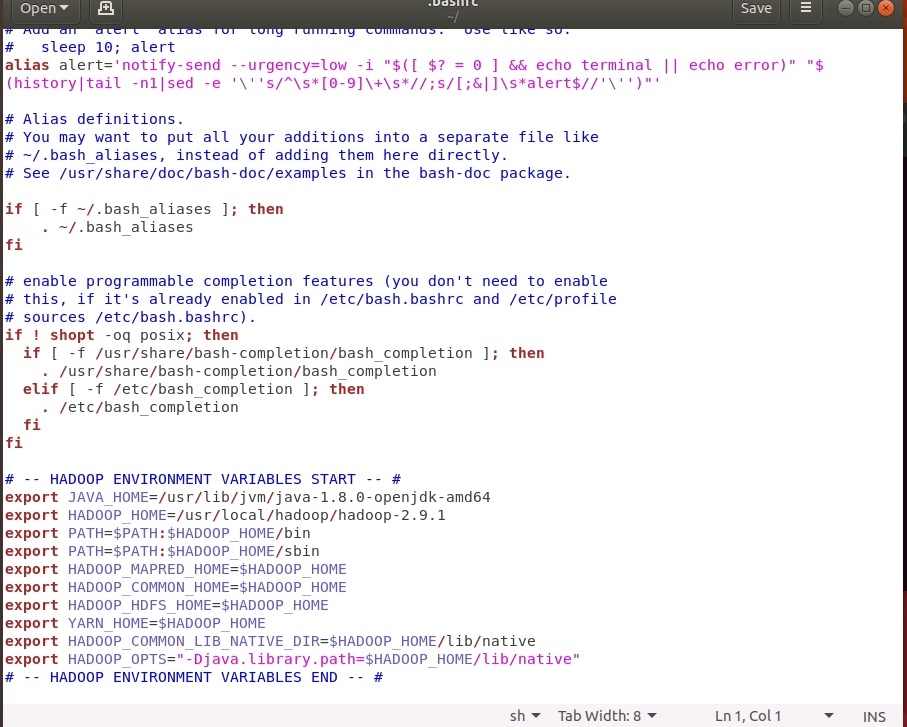
.
Настраиваем HADOOP. Необходимо отметить, что все конфигурационные файлы находятся по следующему пути (в нашей конфигурации): /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/
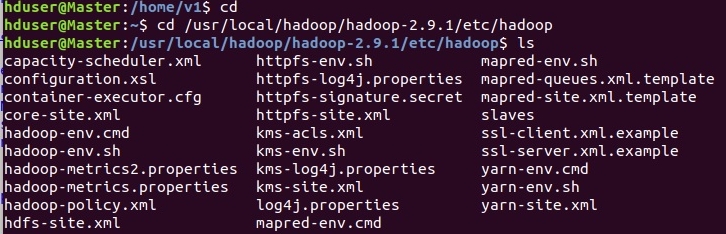
.
Добавить переменную JAVA_HOME в файл /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hadoop-env.sh
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hadoop-env.sh
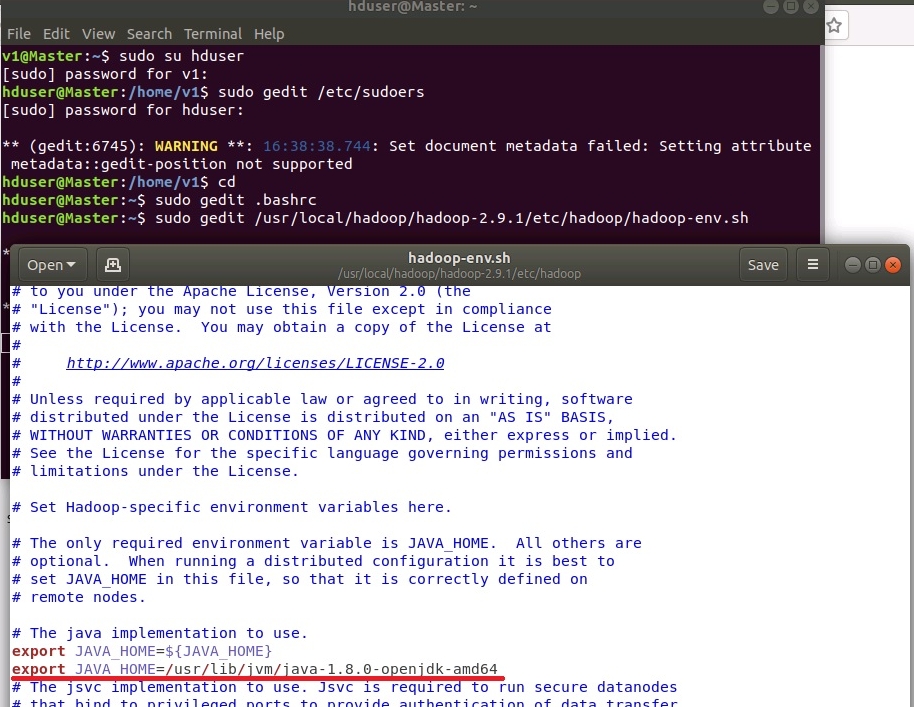
.
Настройка файла core-site.xml. Для этого открыть файл в редакторе с помощью команды
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/core-site.xml
И прописать следующие строки:
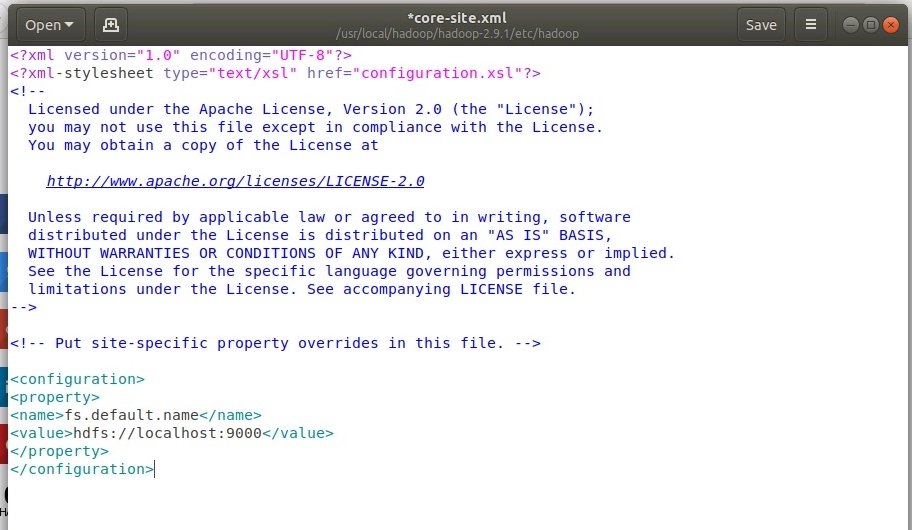
.
Здесь мы указали путь к основной машине (NameNode) файловой системы HDFS, где localhost только для локальной установки HADOOP (в распределенной версии тут либо IP-адрес, либо DNS-имя); 9000 - порт, может быть иным, но лучше не менять.
Настройка файла hdfs-site.xml. Для этого открыть файл в редакторе с помощью команды
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hdfs-site.xml
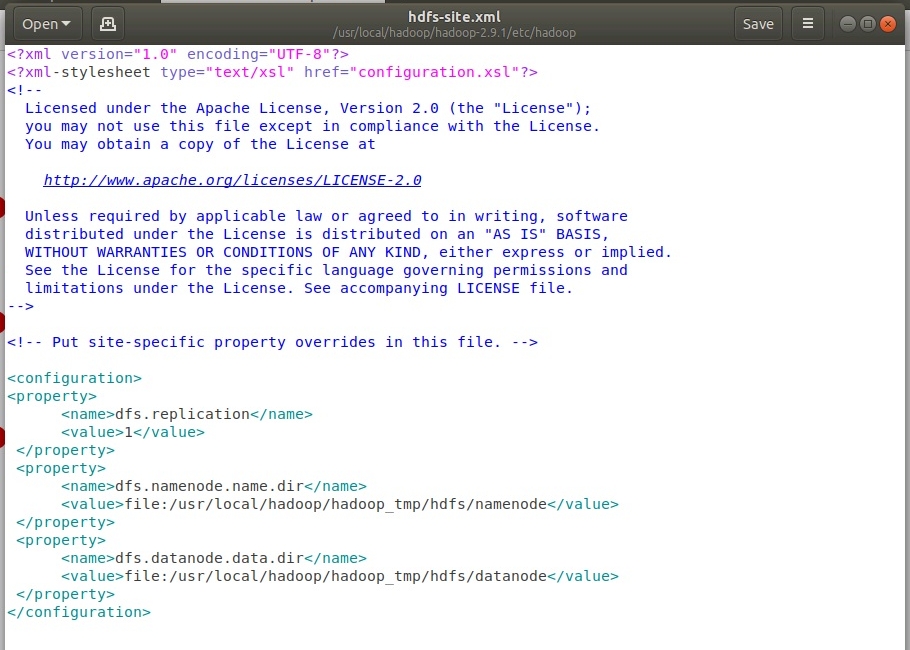
.
Параметры: dfs.replication - количество реплик файлов в HDFS, NameNode - это своеобразная таблица дескрипторов в HDFS (данные о частях и репликах), DataNode - это сами данные.
Настройка yarn-site.xml. Для этого открыть файл в редакторе с помощью команды
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/yarn-site.xml
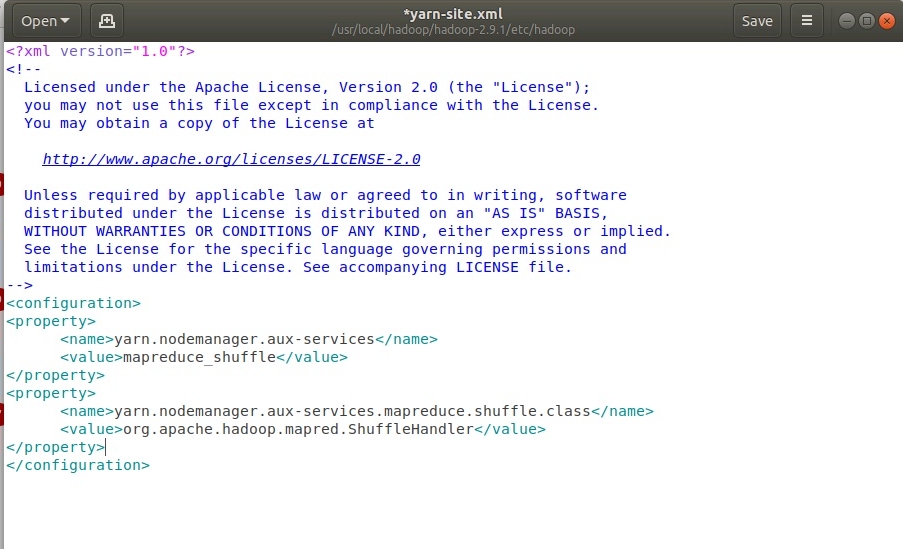
.
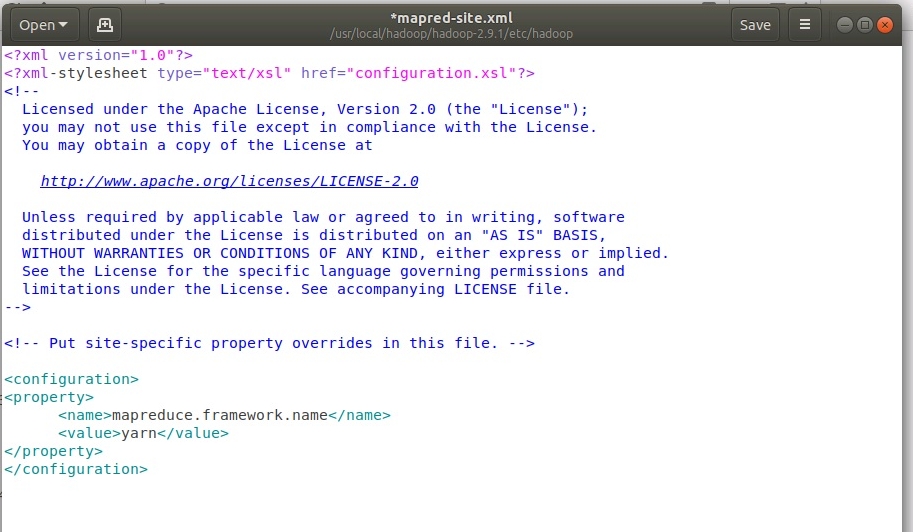
Настройка mapred-site.xml. Файл изначально не существует, есть шаблон, который нужно скопировать командой:
cp /usr/local/hadoop//hadoop-2.9.1/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml
Открыть и отредактировать созданный файл
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml
.
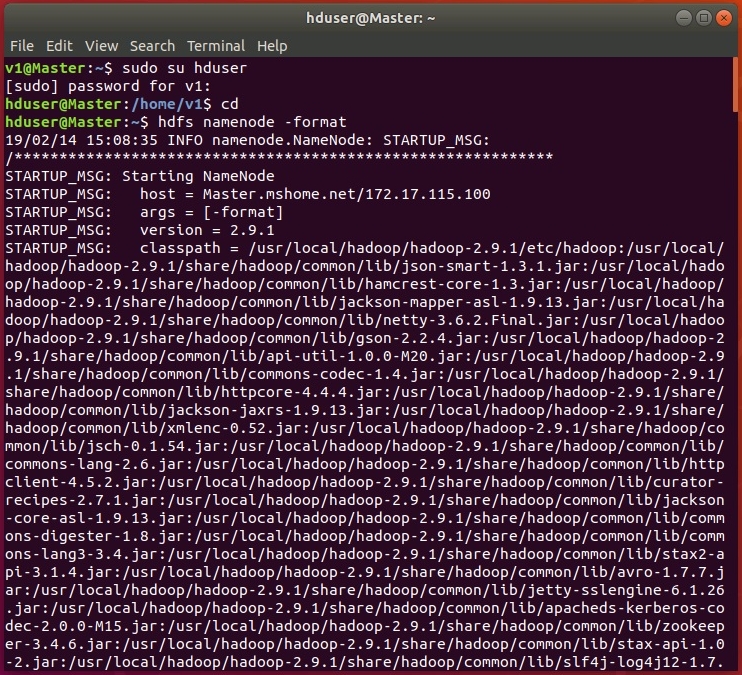
На этом настройка закончена, перезагружаем систему и форматируем HDFS от пользователя hduser с помощью команды:
hdfs namenode -format
В ходе форматирования в терминале будут отображены логи:
.
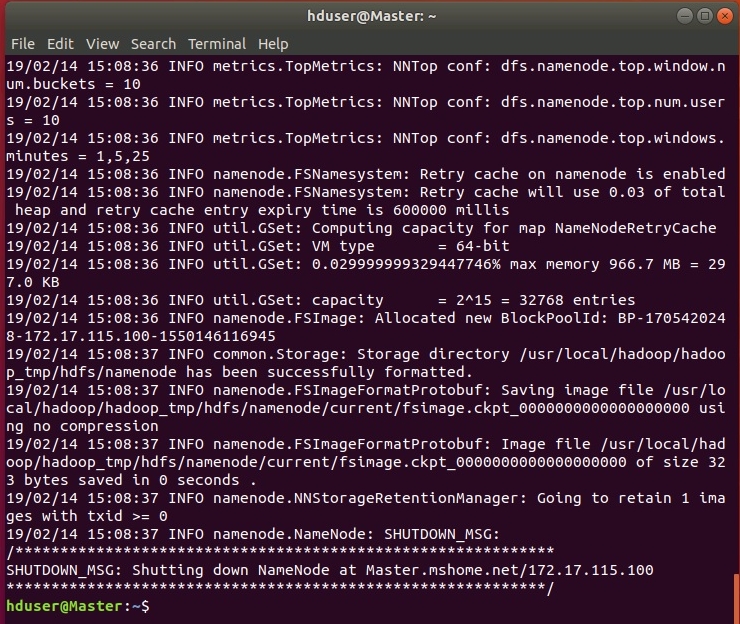
Если все настроено правильно, в логах не должно быть записей, содержащих ERROR, WARN допускаются. При удачном форматировании конец логов должен выглядеть приблизительно так:
.
Теперь осталось запустить HADOOP!
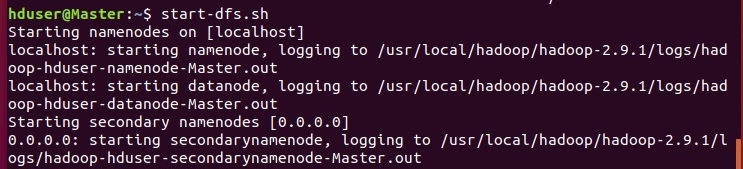
Запуск HADOOP заключается в запуске менеджеров HDFS и YARN. Для этого необходимо запустить два скрипта.
Для HDFS - start-dfs.sh
.
Для YARN - start-yarn.sh

.
Успешность запуска всех демонов HADOOP можно проверить с помощью команды jps.
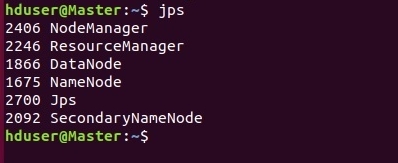
.
Если все настроено правильно, должно быть запущено 5 процессов HADOOP: NodeManager, NameNode, DataNode, ResourceManager, SecondaryNameNode.
Для облегчения процедуры запуска HADOOP можно создать простой скриптик, для этого перейдем в домашний каталог пользователя hduser с помощью команды cd.
Создадим файл hdp.sh и отредактируем его с помощью команды:
sudo gedit hdp.sh
Добавим в редакторе следующие строки:
/usr/local/hadoop/hadoop-2.9.1/sbin/start-dfs.sh
/usr/local/hadoop/hadoop-2.9.1/sbin/start-yarn.sh
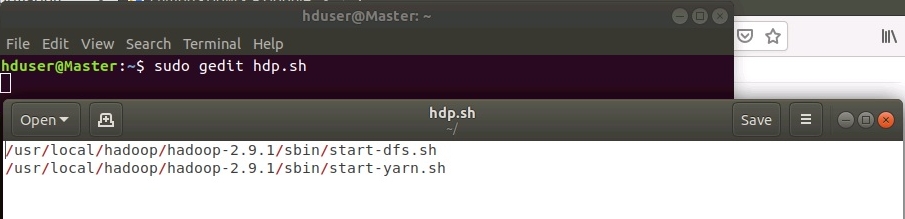
.
Сохраняем и выходим. Теперь нужно дать права на исполнения для файла hdp.sh. Это делается командой:
sudo chmod 777 hdp.sh
Запускаем наш скрипт:
./hdp.sh
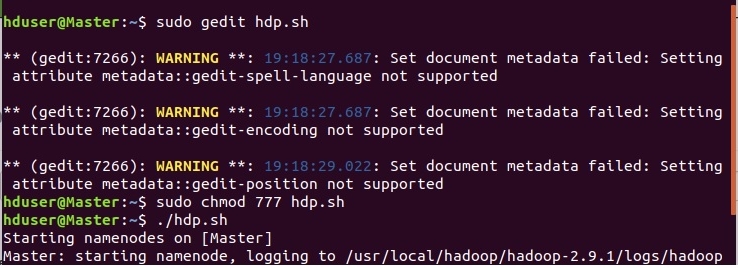
.
Вот мы и настроили однонодовый кластер HADOOP. В следующей статье будет представлена настройка многонодового кластера.
Комментарии

вроде всё вручную запускается, но после данных инструкций, когда я уже позабыл про hadoop и система перезагружалась
стал появляться процесс kswapd0 под юзером hduser, ещё и 50% ЦПУ кушает, также под юзером hduser два процесса rsync
..kswapd0 пишут что своп это, но он же не должен под hduser быть? исследовал systemd, cron, X-вый автостарт - безрезультатно
Комментировать могуть только зарегистрированные пользователи
За статьи по Hadoop большое спасибо, они у вас все классные!!