
Оглавление:
1. Описание архитектуры кластера HADOOP.
2. Настройка кластера HADOOP.
Описание архитектуры кластера HADOOP.
В предыдущем разделе мы научились настраивать однонодовый кластер HADOOP. То есть на одной машине (физической или виртуальной) развернуты основные компоненты базиса HADOOP - файловой системы HDFS, NameNode и DataNode. В кластерной системе предлагается разделять эти компоненты по разным машинам. Master - это управляющая машина кластера, на которой развернута своеобразная таблица дескрипторов HDFS - NameNode. Поэтому на мастере обычно установлена серверная ОС. Остальные машины кластера в нашем примере будут подчиненными - Slave, на которых развернуты DataNode, те части файловой системы, на которых хранятся данные.
Важным параметром HDFS является репликация (replication) и размер блока данных (Block_size). Репликация отвечает за отказоустойчивость, в данном случае реплики блоков данных хранятся на разных подчиненных машинах, то есть дублируются. Рекомендованным значением параметра репликации является 3(три), именно поэтому мы будем разворачивать 3 DataNode. Блок данных - стандартный параметр для файловой системы. Для HDFS по умолчанию это значение равно 256 Мб, это значит, что файлы будут нарезаться на блоки данного размера. Это большие данные, поэтому тут не мелочатся. Дело в том, что передавать по сети блоки данных маленького размера неоптимально.

Таким образом, развернем кластер HADOOP из 3-х виртуальных машин: Master - это уже настроенная однонодовая виртуалка, но для экономии памяти и диска мы развернем на ней NameNode и DataNode. Slave - две виртуальные машины под управлением ОС Ubuntu 18.04.2 LTS. На них будут установлены только DataNode.
Приступим к созданию кластера, для этого необходимо создать 2 виртуальные машины под управлением ОС Ubuntu любой версии. Я не стал возиться, и установил на обе Ubuntu 18.04.2 LTS с визуальным интерфейсом. Планировал клонировать машины, но как оказалось, есть много подводных каменей c идентификаторами и МАС-адресами у Hyper-V (вот и первые недостатки).
Настройка кластера HADOOP.
Теперь у нас есть 3 виртуальные машины, пока оставим в покое уже настроенную, которая будет выступать в роли Мастера.
На вновь созданных виртуалках нужно сделать следующее: изменить имена машин. Открываем файл в текстовом редакторе:
sudo gedit /etc/hostname
Где нужно дать удобные имена своим подчиненным машинам, я дал им имена 1VM и 2VM. Сохранить изменения и перезагрузить машины.
Так как мы используем Hyper-V, нам не надо заботиться о службе доменных имен, наши виртуалки уже знают имена друг друга. Это можно проверить, набрав команду в терминале 1VM:
ping 2VM
или
ping Master
В случае успеха, пойдут ответы от пингуемых, как на рисунке.
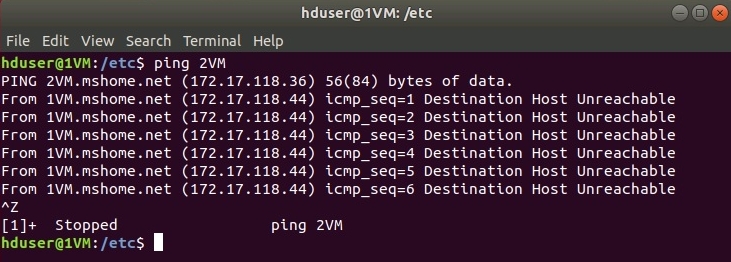
Если ответа нет, значит надо внести изменения в файл /etc/hosts, где прописать имена и IP-адреса всех машин кластера на каждой виртуальной машине:
sudo gedit /etc/hosts
Добавить строки (IP-адреса приведены для примера, у вас будут другие):
192.168.2.1 Master
192.168.2.2 1VM
192.168.2.3 2VM
Далее на каждой новой виртуалке создать группу hadoop, пользователя hduser и добавить пользователя в sudoers:
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
sudo usermod -a -G sudo hduser
Установить JAVA на каждой из машин:
sudo apt install openjdk-8-jdk-headless
sudo apt install openjdk-8-jre-headless
Установить SSH-сервер:
sudo apt install openssh-server
Установить утилиту rsync на каждой из машин:
sudo apt-get install rsync
Данной утилитой мы в дальнейшем скопируем с Мастера все настройки.
После этого перезагрузить виртуалки.
Теперь приступим к изменению конфигурации на Мастере.
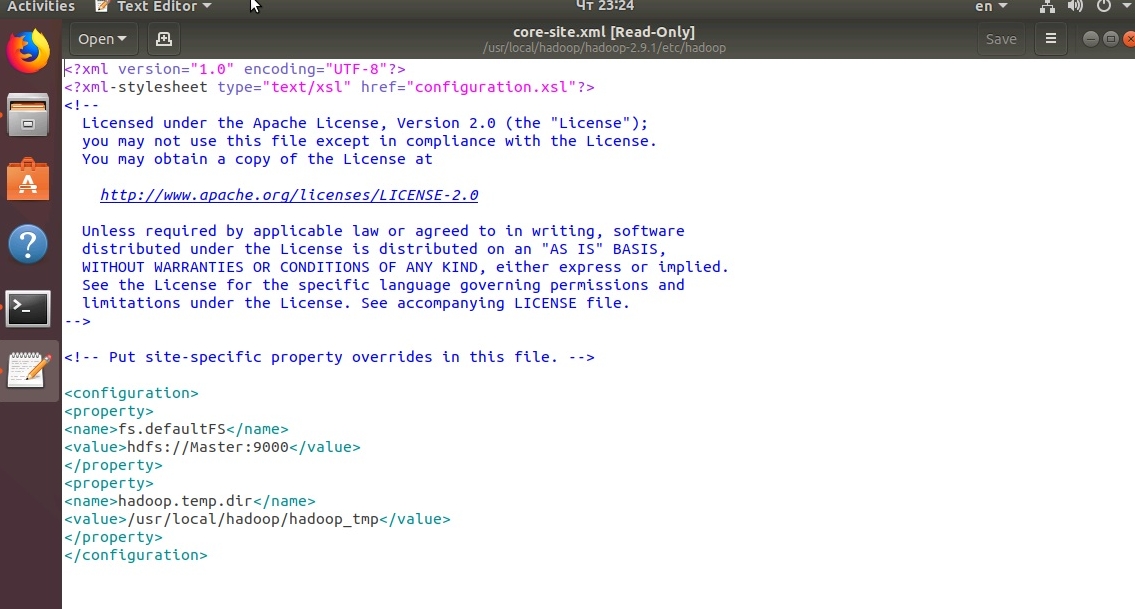
Первым делом внесем изменения в файл core-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/core-site.xml как представлено на рисунке:
Файл hdfs-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/hdfs-site.xml как представлено на рисунке:

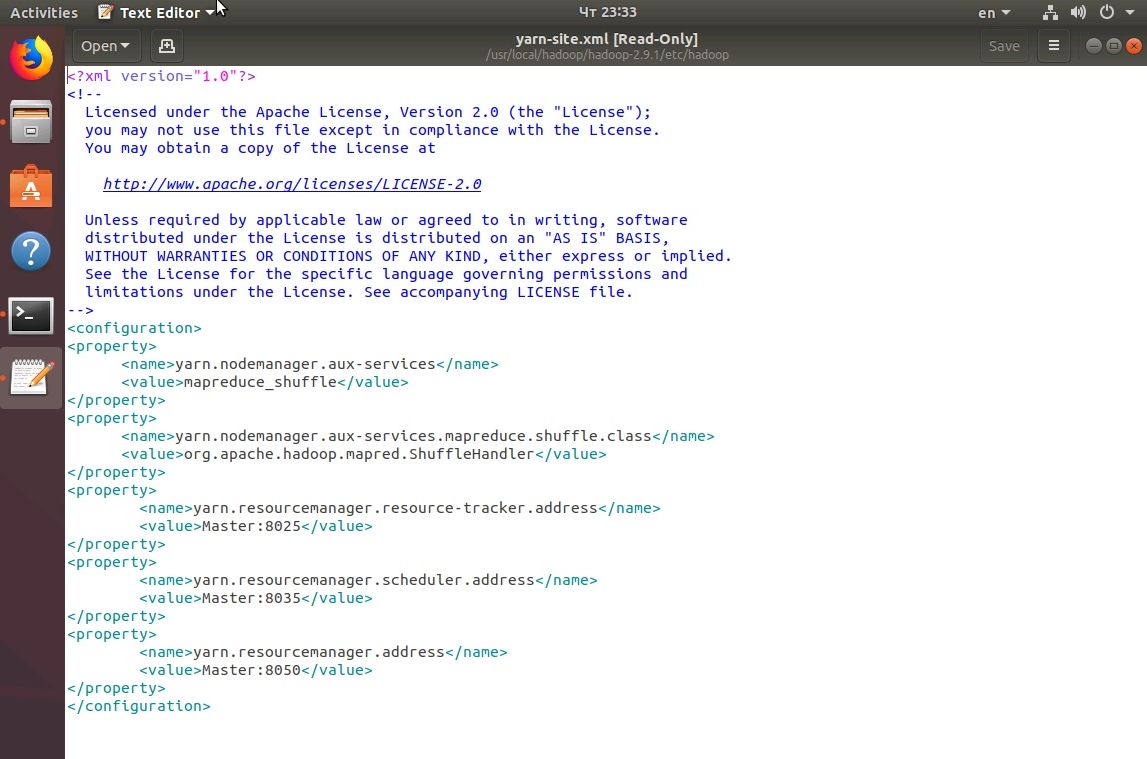
Файл yarn-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/yarn-site.xml как представлено на рисунке:
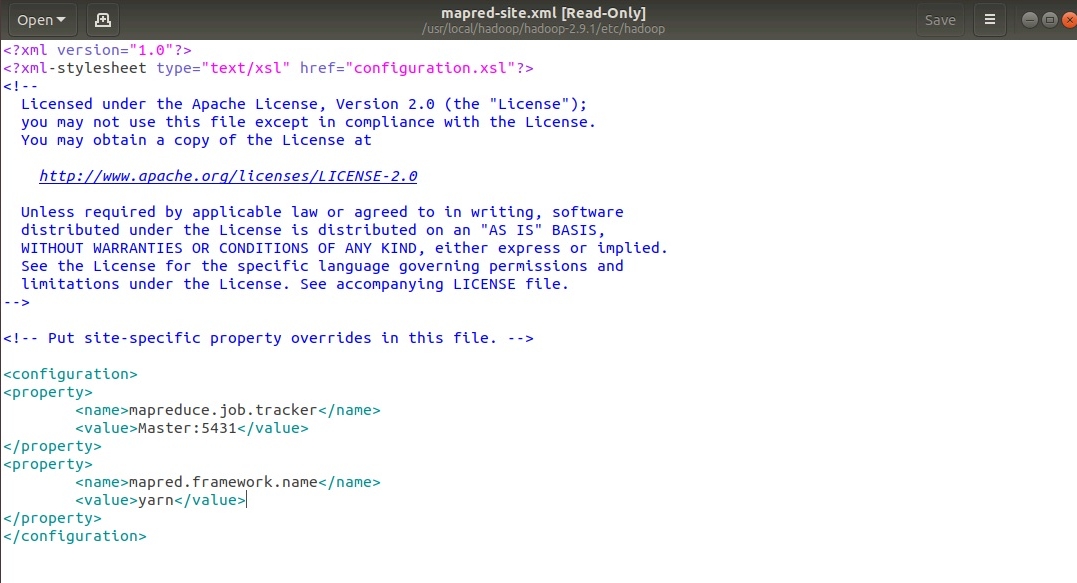
Файл mapred-site.xml:
sudo gedit /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/mapred-site.xml как представлено на рисунке:
Итак, мы уже близки к успеху, теперь надо прописать имена Мастеров и подчиненных в настройках. Это делается через файлы masters и slaves в каталоге /usr/local/hadoop/hadoop-2.9.1/etc/hadoop/. С помощью следующей команды откроем файл Masters:
sudo gedit masters
Так как мастер у нас один, то надо написать всего лишь его имя - Master.
Далее открываем так же файл slaves и прописываем там 3 подчиненных хоста (Master 1VM 2VM через Enter):

.
Практически все настроено, осталось скопировать данные настройки на подчиненные машины и подготовить каталоги файловой системы HDFS.
Копируем настройки на подчиненные машины:
sudo rsync -avxP /usr/local/hadoop/ hduser@1VM:/usr/local/hadoop/
и на вторую:
sudo rsync -avxP /usr/local/hadoop/ hduser@2VM:/usr/local/hadoop/
Копируем ключи SSH на подчиненные машины:
hduser@Master: ~$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub hduser@1VM
и на вторую:
hduser@Master: ~$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub hduser@2VM
Последний шаг настройки - удаление старых каталогов HDFS.
Для этого на мастере и подчиненных узлах нужно удалить каталоги /usr/local/hadoop/hadoop_tmp/:
sudo rm -rf /usr/local/hadoop/hadoop_tmp/
Далее на мастере! создать каталоги namenode и datanode, так как мастер-машина у нас одновременно мастер и подчиненная.
Команды:
sudo mkdir -p /usr/local/hadoop/hadoop_tmp/hdfs/namenode
sudo mkdir -p /usr/local/hadoop/hadoop_tmp/hdfs/datanode
Затем назначить владельцем каталога пользователя hduser группы hadooop:
sudo chown hduser:hadoop -R /usr/local/hadoop/hadoop_tmp/
На подчиненных машинах сделать тоже самое, но создать только каталог datanode:
sudo mkdir -p /usr/local/hadoop/hadoop_tmp/hdfs/datanode
sudo chown hduser:hadoop -R /usr/local/hadoop/hadoop_tmp/
Теперь все готово, отформатируем файловую систему, выполнив команду на Мастере:
hdfs namenode -format
Если нет ошибок, запустим hdfs и yarn с помощью скрипта из первой части, либо командами:
start-dfs.sh
start-yarn.sh
В случае успеха с помощью команды jps можно посмотреть запущенные java-процессы на мастере:
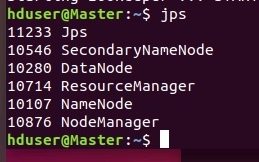
На подчиненных машинах:
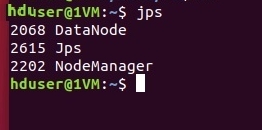
.
При успешной настройке также запускаются WEB-интерфейсы hdfs и задач MR в hadoop.
Интерфейс задач доступен по адресу http://Master:8088
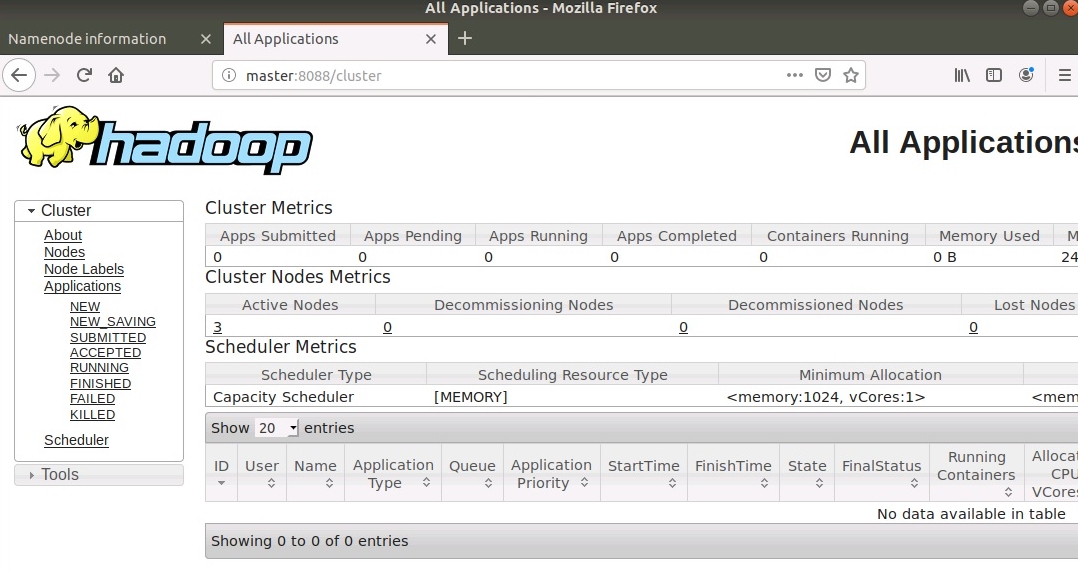
.
Интерфейс состояния HDFS доступен по адресу http://Master:50070
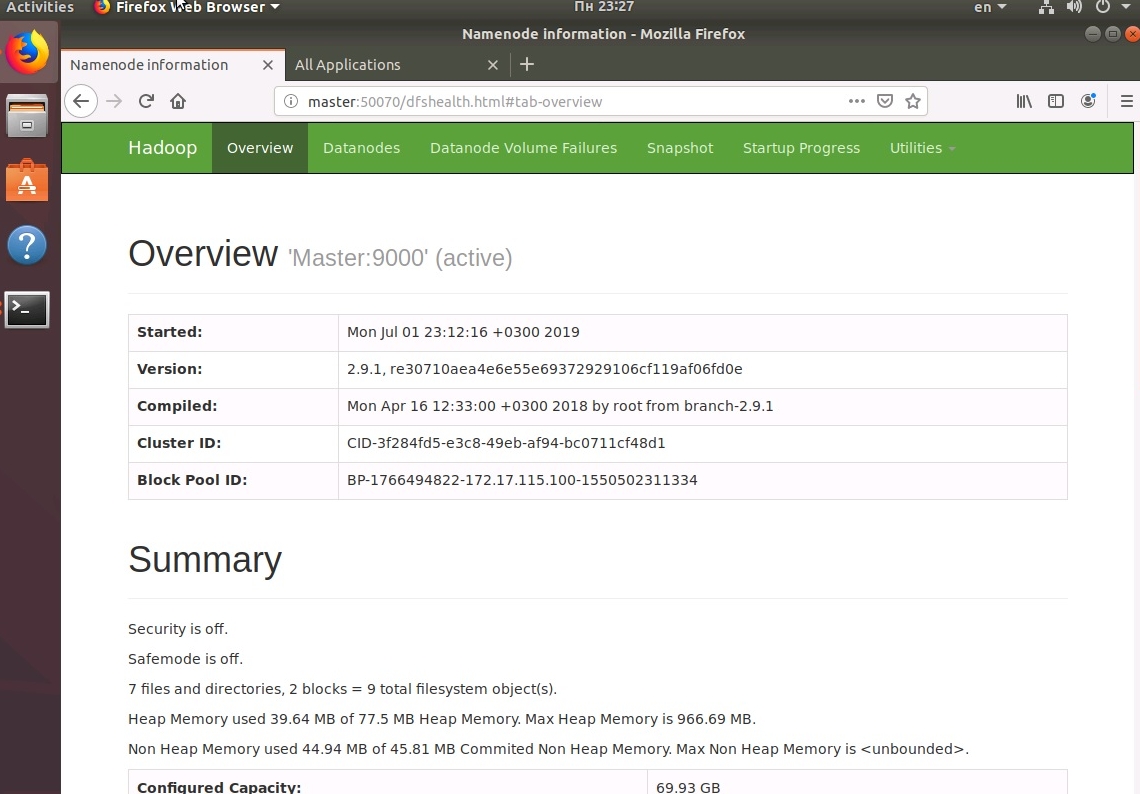
.
На этом этап настройки закончен, далее будем выяснять, зачем же это все нужно.
Комментарии
Комментировать могуть только зарегистрированные пользователи