
Оглавление:
1. Что такое Apache Kafka .
2. Установка и настройка Apache Kafka .
3. Работа с очередями Apache Kafka.
Что такое Apache Kafka .
Apache Kafka - это платформа распределенной потоковой передачи событий с открытым исходным кодом, используемая тысячами компаний для высокопроизводительных конвейеров данных, потоковой аналитики, интеграции данных и критически важных приложений.
Потоковая передача событий - это сбор данных в реальном времени из источников событий, таких как базы данных, датчики, мобильные устройства, облачные сервисы и программные приложения в форме потоков событий; долговременное хранение этих потоков событий для последующего извлечения; манипулирование, обработка и реагирование на потоки событий в реальном времени, а также ретроспективно; маршрутизация потоков событий к различным технологиям назначения по мере необходимости. Таким образом, потоковая передача событий обеспечивает непрерывный поток и интерпретацию данных, так что нужная информация находится в нужном месте в нужное время.
Kafka сочетает в себе три ключевые возможности, поэтому можно реализовать свои варианты использования для сквозной потоковой передачи событий с помощью единого решения:
1. Для того, чтобы опубликовать (запись) и подписаться на (чтение) потоков событий, в том числе непрерывного импорта / экспорта данных из других систем.
2. Для надежного хранения потоков событий столько, сколько необходимо.
3. Для обработки потоков событий по мере их возникновения или ретроспективно.
Все эти функции предоставляются в распределенном, высокомасштабируемом, отказоустойчивом и безопасном виде. Kafka можно развернуть на «голом железе», виртуальных машинах и контейнерах, как локально, так и в облаке.
Kafka - это распределенная система, состоящая из серверов и клиентов, которые обмениваются данными через высокопроизводительный сетевой протокол TCP.
Серверы : Kafka работает как кластер из одного или нескольких серверов, которые могут охватывать несколько центров обработки данных или облачных регионов. Некоторые из этих серверов образуют уровень хранения, называемый брокерами. На других серверах работает Kafka Connect для непрерывного импорта и экспорта данных в виде потоков событий для интеграции Kafka с вашими существующими системами, такими как реляционные базы данных, а также с другими кластерами Kafka. Чтобы обеспечить возможность реализации критически важных вариантов использования, кластер Kafka отличается высокой масштабируемостью и отказоустойчивостью: если какой-либо из его серверов выходит из строя, другие серверы берут на себя их работу, чтобы обеспечить непрерывную работу без потери данных.
Клиенты : позволяют писать распределенные приложения и микросервисы, которые считывают, записывают и обрабатывают потоки событий параллельно, масштабно и отказоустойчивым образом даже в случае сетевых проблем или сбоев машины. Kafka поставляется с некоторыми такими включенными клиентами, которые дополняются десятками клиентов, предоставляемых сообществом Kafka: доступны клиенты для Java и Scala, включая высокоуровневую библиотеку Kafka Streams , для Go, Python, C/C ++ и многих других языков программирования, а также REST API.
Установка и настройка Apache Kafka.
Обратите внимание, для работы Apache Kafka требуется Zookeeper, установка и настройка которого рассмотрена в предыдущем разделе.
Установка:
1. Скачать требуемую версию с официального сайта.
У меня стабильно работает версия 2.3.0 (на сайте Scala 2.12 - kafka_2.12-2.3.0.tgz).
2. Распаковать содержимое архива в каталог /usr/local/kafka-2.3.0 (может быть и другой). Назначить владельцем данного каталога пользователя hduser (данного пользователя мы создали ранее для всей экосистемы. У вас может быть другой, например kafka).
3. Создать каталог /usr/local/kafka-2.3.0/kafka-logs.
4. Редактируем файл настроек server.properties в каталоге /usr/local/kafka-2.3.0/config.
Указать следующие значения:
broker.id=1 - данное значение уникально для каждого сервера (брокера сообщений Kafka), у меня 1,2,3
listeners=PLAINTEXT://master.mshome.net:9092 - имя и порт, для каждого сервера уникальны (другие два: 3VM.mshome.net:9093, 4VM.mshome.net:9094).
log.dirs=/usr/local/kafka-2.3.0/kafka-logs - каталог для логов, мы его создали на шаге 3.
zookeeper.connect=master.mshome.net:2181,3VM.mshome.net:2182,4VM.mshome.net:2183 - адреса и порты серверов Zookeeper, указаны в настройках, файл zoo.cfg.
Сохранить изменения.
5. Скопировать каталог kafka-2.3.0 на все ноды кластера.
6. Внести изменения (broker.id и listeners) в файл server.properties на всех нодах.
Настройки закончены, можно запускать сервер!
Запуск сервера Kafka:
sudo /usr/local/kafka-2.3.0/bin/kafka-server-start.sh /usr/local/kafka-2.3.0/config/server.properties:
Остановка сервера Kafka:
sudo /usr/local/kafka-2.3.0/bin/kafka-server-stop.sh
Работа с очередями Apache Kafka.
В Kafka используются следующие термины:
topic - уникальное название темы (очереди), в которую помещаются сообщения
produser - приложение, которое помещает сообщения в темы (topic) Kafka
consumer - приложение, которое читаем сообщения из темы (topic) Kafka
Сначала необходимо создать тему (все скрипты для запуска в каталоге /usr/local/kafka-2.3.0/bin/):
sudo ./kafka-topics.sh --create --zookeeper master:2181 --replication-factor 3 --partitions 3 --topic kafka1

--zookeeper master:2181 - Zookeeper-сервер, может быть любой доступный
--replication-factor 3 - репликация, значение не должно превышать количество доступных Kafka-брокеров
--partitions 3 - количество разделов, определяется количеством подписчиков (consumer)
--topic kafka1 - название темы (topic) Kafka
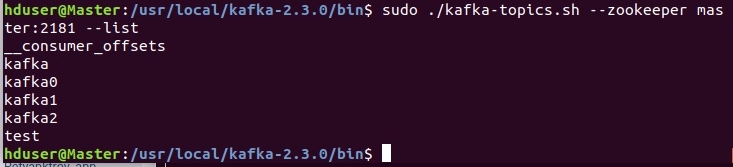
Список доступных тем:
sudo ./kafka-topics.sh --zookeeper master:2181 --list
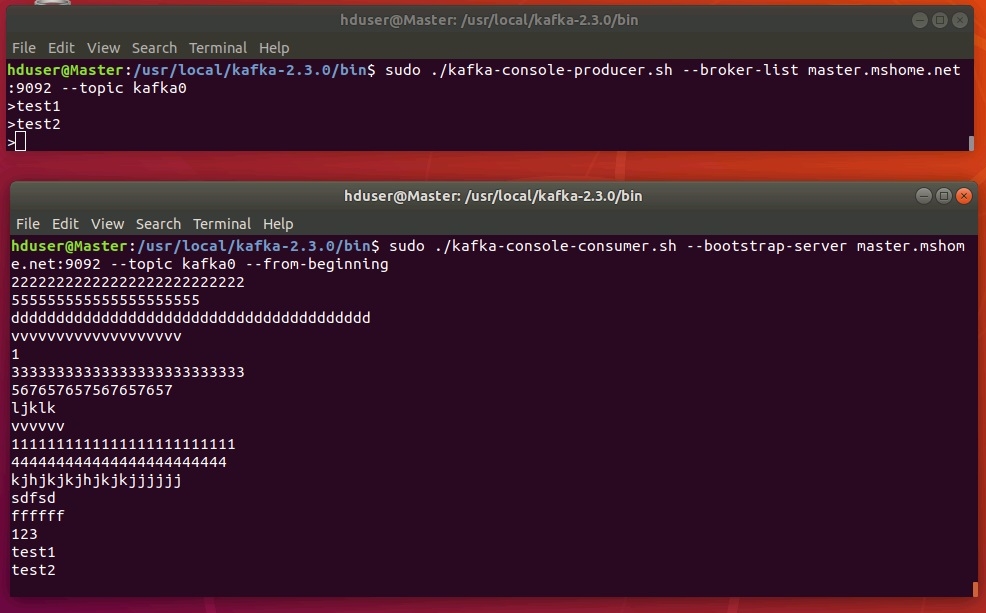
Теперь попробуем писать сообщения в созданную тему и тут же читать из нее. Для наглядности лучше запустить два терминала, один для produser, второй - для consumer.
Запуск produser:
sudo ./kafka-console-producer.sh --broker-list master.mshome.net:9092 --topic kafka1
--broker-list master:9092 - любой из доступных kafka-брокеров (серверов)

Во время экспериментов произошел показательный случай, отвалился один из серверов kafka. Поэтому consumer для темы kafka1 искал постоянно третьего, так как был задан replication-factor 3.
Поэтому на скриншотах представлена тема kafka1 с replication-factor 3.
Запуск consumer:
sudo ./kafka-console-consumer.sh --bootstrap-server master.mshome.net:9092 --topic kafka0 --from-beginning
Комментарии
Комментировать могуть только зарегистрированные пользователи